Flux RSS
Développement
1816 documents trouvés, affichage des résultats 21 à 30.
| < Les 10 documents précédents | Les 10 documents suivants > |
(27/01/2012 12:28:02)
Test logiciel : Sogeti livre une boîte à outils TMap sur iOS et Android
Les spécialistes du test et de la qualité des logiciels disposent avec TMap Life Cycle d'une application mobile pour iOS et Android leur permettant de suivre la progression de leurs projets au long du processus de contrôle. TMap Life Cycle est mis à disposition gratuitement par Sogeti sur l'App Store et l'Android Market. La méthodologie de gestion de test logiciel structurée TMap (Test Management Approach) a été créée par Sogeti Pays-Bas il y a une vingtaine d'années. Une méthode fondée sur le « risk-based testing » qui convient à tout type d'organisation et à toutes situations de test dans la plupart des environnements de développement, explique Sogeti sur son site.
L'application mobile pour Android, iPhone, iPod Touch et iPad décrit les différentes phases de TMap Life Cycle et propose de télécharger des checklists et des modèles supportant le processus TMap. Elle comporte des vidéos de démonstration de conception des tests, l'analyse de risque produit et des méthodes pour déterminer des stratégies de test, décrit la SSII. Elle donne aussi accès au téléchargement d'e-Books et de livres blancs. Autant de contenus spécialisés mis ainsi à portée de main des professionnels du test.
La version Android de TMap Life Cycle
Ruby on Rails passe en version 3.2
Ruby on Rails est un framework Open Source, lancé en 2004, pour la création d'applications web basées sur le langage de développement Ruby. Aujourd'hui, la plateforme évolue vers la version 3.2. Un des principaux atouts est l'amélioration du mode développement. David Heinemeier Hansson, créateur de Ruby on Rails, explique dans un blog, « l'accélération du mode dev est une étape majeure depuis la version 3.1 [qui est sortie en août 2011] ». Cela signifie qu'à chaque fois qu'un programme est modifié, puis testé, le mode dev ne recharge que les classes réellement modifiées. «La différence est spectaculaire sur une grosse application », précise David Heinemeier Hansson.
Marqueur et moteur de routage intégré
La fonctionnalité « tagg loader » est aussi une innovation de la version 3.2. Il s'agit de marqueurs pour savoir si Ruby on Rails est utilisé pour exécuter plusieurs applications ou s'il lance une application pour plusieurs utilisateurs. Avec ce script, un administrateur peut filtrer les fichiers log, juste pour voir l'activité d'une application ou d'un utilisateur spécifique. Une autre fonctionnalité permet d'annoter les requêtes - qui peuvent aider au débogage - et la version 3.2 intègre un moteur de routage, appelé Journey, pour accélérer les réponses aux demandes des navigateurs web.
Au moins 226 000 sites utilisent Ruby on Rails, selon le service australien BuiltWith analyse des tendances Pro. Dans l'enquête de TIOBE sur les langages, publiée en Janvier, l'utilisation de Ruby semble avoir légèrement reculé.
(...)
Android 4.0 est disponible pour la TouchPad de HP
Ice Cream Sandwich s'invite officiellement sur la TouchPad de HP. CyanogenMod est un groupe de développeurs qui s'est créé après l'annonce de l'abandon par le constructeur de la fabrication des tablettes. Il a présenté publiquement CM9 (CyanogenMod9) en version Alpha qui porte Android 4.0 sur la TouchPad. Les indications Alpha 0 montre que certaines fonctionnalités ne sont pas prises charge, comme la gestion des codes vidéos ou la caméra.
Il s'agit néanmoins de la première version issue de la décision de Google de rendre disponible le code source d'Android 4.0. Les développeurs de Cyanogen appellent donc d'autres programmeurs à améliorer ce portage et à corriger les bugs existants.
Pour les novices en informatique, il faudra attendre un peu pour avoir une version stable de la solution de migration. Pour les technophiles, ils peuvent retrouver les informations à télécharger et la documentation pour l'installation sur le site Rootzwiki.
(...)
IBM acquiert Green Hat, spécialiste de logiciel de tests
Pour renforcer son offre d'outils de test, IBM vient de racheter Green Hat. Cette dernière propose une plateforme virtuelle de tests. Elle donne aux développeurs les moyens de tester les applications sans avoir besoin de configurer physiquement des environnements de tests. Cela permet d'économiser du temps et de l'argent souligne IBM. Le constructeur ajoute que les cycles de développement sont devenus plus rapides avec l'essor des smartphones et des tablettes.
Les produits de Green Hat seront intégrés au sein de la division Rational d' IBM, qui offre déjà plusieurs logiciels et outils de tests. Alors quel est le sens de ce rachat, « je pense que Green Hat va étendre les capacités actuelles de Rational Quality Manager », déclare Jeffrey Hammond analyste chez Forrester Research et de mentionner à titre d'exemple « le support de Netweaver de SAP et Fusion Middleware d'Oracle ». Le site de Green Hat rajoute dans la liste les middleware de Tibco, Software AG et Progress Software, etc. Jeffrey Hammond précise « le support des tests sur les services REST (Representational State Transfer) apportera une valeur ajoutée pour Rational. Avec l'augmentation des services web basés sur XML et JSON, nous constatons que de plus en plus d'entreprises construisent des plateformes de tests pour s'assurer de la fonctionnalité des API ».
Facebook lance sa 3ème Hacker Cup
Pour mettre au défi les programmeurs dans le monde, Facebook a lancé son concours Hacker Cup. C'est la troisième édition de cette compétition un peu particulière. « Le hacking est au coeur de notre façon de développer sur Facebook », a écrit David Alves, ingénieur chez Facebook, sur le blog annonçant le concours. Les sociétés reposant sur des ingénieurs sont « toujours à la recherche de solutions de type hacking pour résoudre les problèmes », a-t-il dit.
Facebook se sert de la définition originale de «hacker», se référant non pas à quelqu'un qui s'introduit illégalement dans les systèmes informatiques, mais plutôt à une personne qui « aime explorer en détail les programmes et essaye d'étendre leurs capacités », pour emprunter la définition publiée par la bible du jargon informatique, le dictionnaire anglo-saxon The Jargon File.
Les quatre premières manches du concours se dérouleront en ligne, à partir du 28 janvier. Les 25 finalistes seront invités au siège de Facebook pour une dernière épreuve le 27 mars prochain. Le gagnant repartira avec 5 000 dollars, et les trois autres finalistes recevront aussi une récompense pécuniaire. Le concours se compose d'une série successive de problèmes algorithmiques de plus en plus difficiles. La notation sera basée sur la précision et la rapidité des développeurs à résoudre les casse-têtes.
Des casse-têtes très geek
L'année dernière, les principaux défis portaient sur la détermination du nombre optimal de générateurs de boucliers et de guerriers Protoss qu'un joueur devait construire au jeu Starcraft II et l'estimation de la meilleure stratégie de course dans un jeu de voitures avec un nombre variable de concurrents, tout en gérant la probabilité d'accidents. Pour chaque problème, les participants reçoivent un ensemble de données et une explication du problème. Ils ont ensuite six minutes pour proposer une réponse, avec le code source utilisé pour résoudre le problème. Les participants peuvent recourir à n'importe quel langage de programmation, ainsi que des bibliothèques de code et même des programmes complets, comme un tableur.
L'année dernière, la Hacker Cup a connu un démarrage difficile. Sur le site de réseautage social Quora, certains candidats s'étaient plaints que les procédures du concours étaient confuses et parfois contradictoires. Pour cette nouvelle édition, le géant des réseaux sociaux a revu les processus pour améliorer la première sélection.
(...)(03/01/2012 16:55:03)22 outils gratuits pour visualiser et analyser les données (1ère partie)
Pour faire parler des données, rien ne vaut une panoplie d'outils de visualisation graphique. Il en existe de nombreux, notamment destinés aux professionnels versés dans l'analyse statistique. Mais leur prix, généralement élevé, ne convient pas aux utilisateurs moins spécialisés qui n'ont besoin qu'occasionnellement d'afficher des données sous une forme graphique. Or, il existe, pour ceux dont le budget est limité, un nombre surprenant d'outils très intéressants pour la visualisation et l'analyse de données, accessibles gratuitement. Au printemps dernier, Sharon Machlis, de Computerworld, en a listé plus de vingt, qu'elle a répartis en neuf catégories : nettoyage de données, analyse statistique, outils et services de visualisation (1ère partie), outils de développement, SIG, analyse de données temporelles, nuages de mots, visualisation de données relationnelles (2ème partie publiée le 5 janvier). Ils permettent de manipuler les données et de les afficher à travers de multiples représentations graphiques. Particulièrement utiles pour faire apparaître des modèles ou des tendances. La plupart d'entre eux avaient été présentés lors de la conférence Computer-Assisted Reporting (la prochaine conférence CAR aura lieu du 23 au 26 février 2012, à Saint-Louis, Missouri).
- Nettoyage de données
Avant toute analyse ou visualisation, les données ont souvent besoin d'être nettoyées, afin de standardiser leur transcription ou de corriger des fautes. Dans une même base, les noms de ville ou de clients, par exemple, peuvent être avoir été saisis de différentes façons (Net York, New York City, NY..., Société Lambda, Lambda, Sté Lambda, Lambda Sarl...). On trouve deux outils destinés à cet usage : DataWrangler et Google Refine.
1 - DataWrangler : uniquement en ligne
Ce service web du groupe Visualization de l'Université de Stanford est conçu pour nettoyer et réarranger les données sous une forme pouvant être reconnues par d'autres logiciels : les tableurs, mais aussi un langage tel que « R », ou des logiciels commerciaux comme Tableau ou Open Source comme Protovis. En cliquant sur une ligne ou une colonne, cet outil va suggérer des modifications. Par exemple, il proposera de supprimer les lignes vides. Il conserve l'historique qui facilite un retour en arrière (undo), une fonctionnalité également disponible dans Google Refine).
Computerworld souligne que la correction des textes se fait simplement. En revanche, le service étant disponible en ligne (à partir de tout navigateur), cela implique que les données transitent vers un site externe, ce qui le rend inapproprié pour des informations internes sensibles. Une version « poste de travail » est prévue. Autre élément important, l'outil est toujours en cours de développement.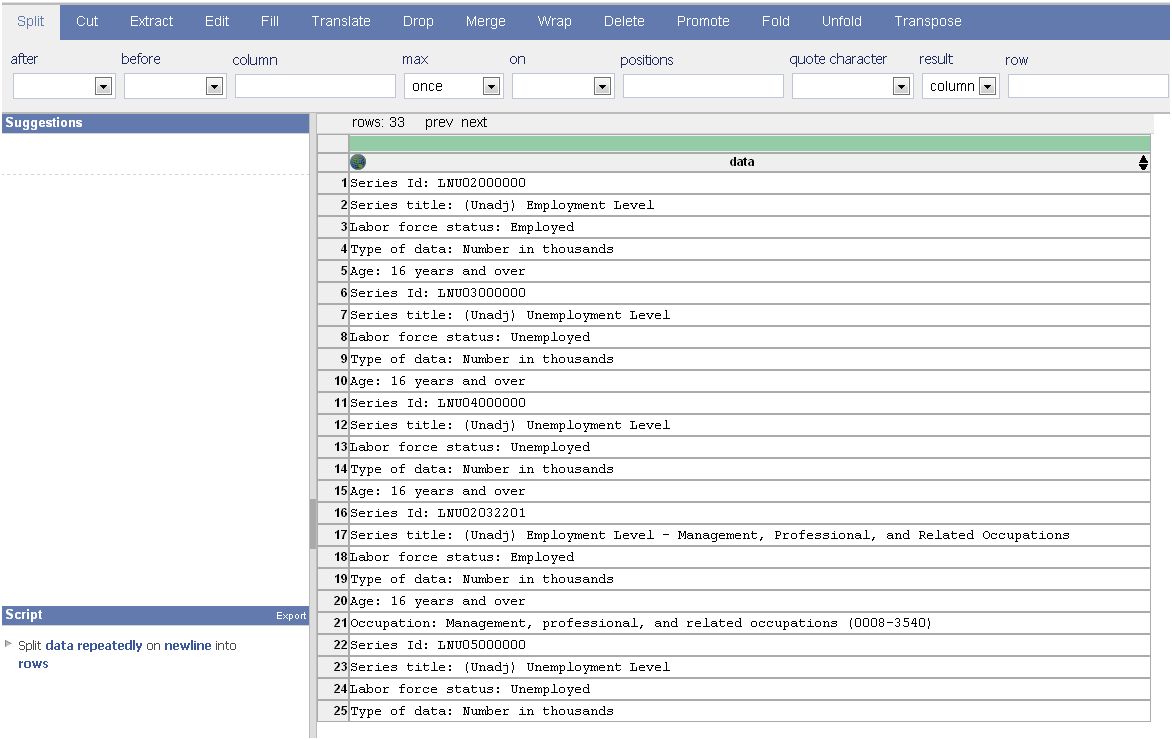
DataWrangler (cliquer ici pour agrandir l'image)
Niveau de compétences requis : débutant avancé.
Fonctionne sur tout navigateur web.
En savoir plus : http://vis.stanford.edu/wrangler/
2 - Google Refine : comme un tableur
Il ressemble à un tableur pour examiner à la fois les données numériques et alphanumériques, mais à l'inverse du tableur, il ne permet pas d'effectuer des calculs. Comme Excel, il peut importer et exporter dans différents formats, incluant les fichiers tabulés, textes, Excel, XML et JSON.
Refine intègre plusieurs algorithmes retrouvant les mots orthographiés différemment mais qui devraient en fait être regroupés. Il y a aussi des options pour passer rapidement en revue les données numériques. Ces fonctionnalités peuvent pointer des anomalies pouvant résulter d'erreurs de saisie, telles que 800 000 dollars à la place de 80 000 dollars pour un salaire par exemple, ou mettre à jour d'autres incohérences. Inconvénient, si le jeu de données est volumineux, son examen peut prendre un certain temps. A noter que Refine propose aussi des outils de tri et de filtre. 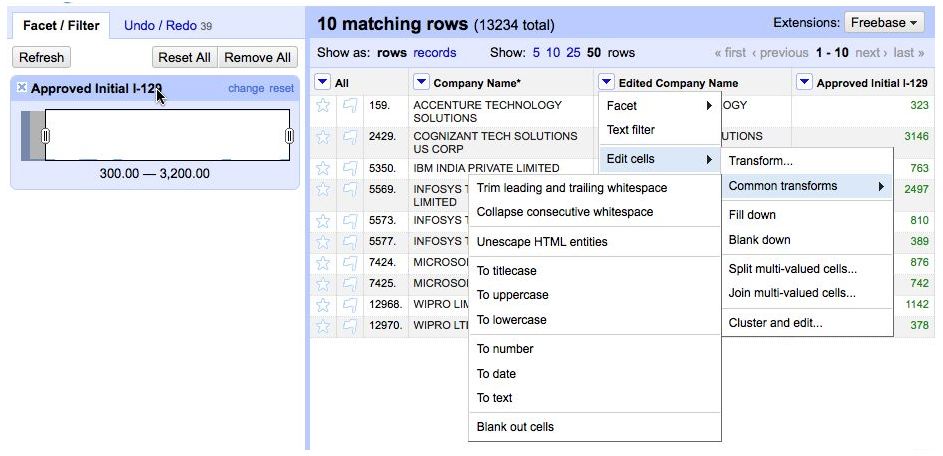
Google Refine (cliquer ici pour agrandir l'image)
Niveau de compétences requis : débutant avancé. La connaissance des concepts d'analyse de données est plus importante que la prouesse technique. Les utilisateurs avancés d'Excel qui ont l'habitude du nettoyage de données devraient être à l'aise avec cet outil.
Google Refine fonctionne sur Windows, Mac OS X et Linux.
En savoir plus : http://code.google.com/p/google-refine/ [[page]]
- Analyse statistique
3 - Le projet R : un langage pour l'univers des statistiques
Projet GNU similaire au langage S, développé par les Laboratoires Bell (anciennement AT&T, désormais Lucent Technologies) par le statisticien John Chambers. Il peut être considéré comme une mise en oeuvre différente de S, même s'il y a d'importantes différences, une grande partie du code écrit pour S fonctionnant de la même façon sous R, explique-t-on sur le site du projet. Il compile et fonctionne sur de nombreuses plateformes Unix, ainsi que sous Windows et MacOS. S'il s'agit de déterminer des moyennes, des valeurs médianes, des écarts types ou des corrélations, R peut le faire et bien plus encore, en incluant les modèles linéaires, les modèles de régression non linéaires, l'analyse des séries chronologiques, les tests paramétriques et non paramétriques, les classifications, le lissage, indique encore le site web. « R » fournit aussi nombre de représentations graphiques, ainsi que des capacités d'analyse spatiale, et se complète de nombreux add-ons.
Inconvénient, l'environnement utilise des lignes de commandes, ce qui nécessite un minimum d'apprentissage pour connaître les commandes à mettre en oeuvre. Pour les utilisateurs qui souhaitent disposer d'une interface graphique, Peter Aldhous, du bureau de San Francisco du magazine New Scientist, suggère RExcel qui propose d'accéder au moteur de R à partir d'Excel. On peut rencontrer une autre limite avec les jeux de données trop importants. Pour la franchir, il existe une option commerciale de la plateforme, fournie par Revolution Analytics.
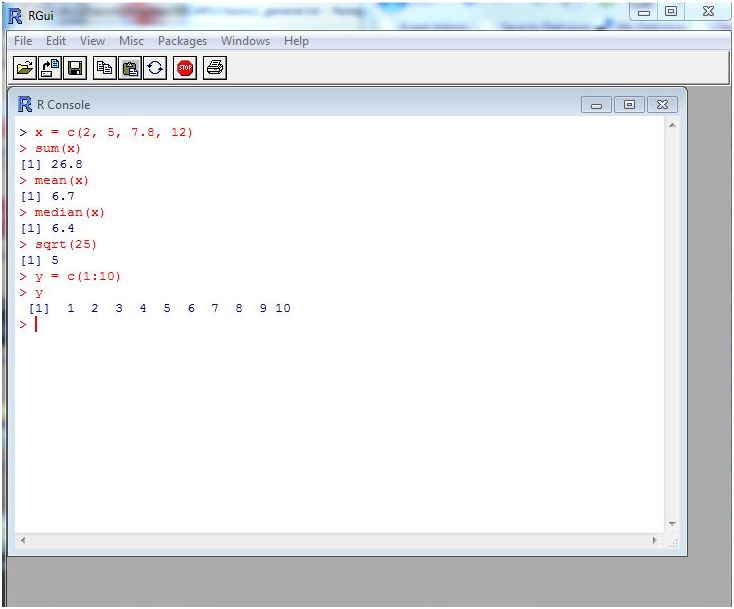
L'environnement R (cliquer ici pour agrandir l'image)
Niveau de compétences : intermédiaire ou avancé. La connaissance des statistiques facilite la prise en main.
R fonctionne sur Linux, Mac OS X, Unix, Windows XP et ultérieurs.
En savoir plus : le projet R
Premiers pas avec R, de Peter Aldhous
- Outils et services de visualisation
Ces outils offrent différentes options de visualisation. Certains se cantonnent aux graphiques conventionnels (représentations sectorielles, histogrammes...), mais la plupart proposent un éventail de choix supplémentaires tels que les Treemap pour afficher les données hiérarchisées ou les nuages de mots. Quelques-uns disposent aussi de représentations géographiques. Dans ce domaine, il existe toutefois des logiciels gratuits spécifiques.
4 - Google Fusion Tables : simple à utiliser et personnalisable
C'est l'une des plus simples façons de transformer des données en graphiques. On met en ligne son fichier (dans différents formats) et on choisit comment l'afficher : sous forme de tableau, de carte, de bargraphe, de camembert, de « heat map », de diagramme de dispersion, d'historique, d'animation... C'est assez personnalisable. Il est notamment possible de changer les icônes des cartes et le style des fenêtres d'information. Fusion Tables comporte aussi des fonctions d'édition de données, quoi que cela devient vite fastidieux dès que l'on commence à devoir modifier au-delà que quelques cellules. On peut aussi faire des jointures de table (important quand les données à afficher se trouvent dans différentes tables), filtrer, trier, ajouter des colonnes et commenter les données.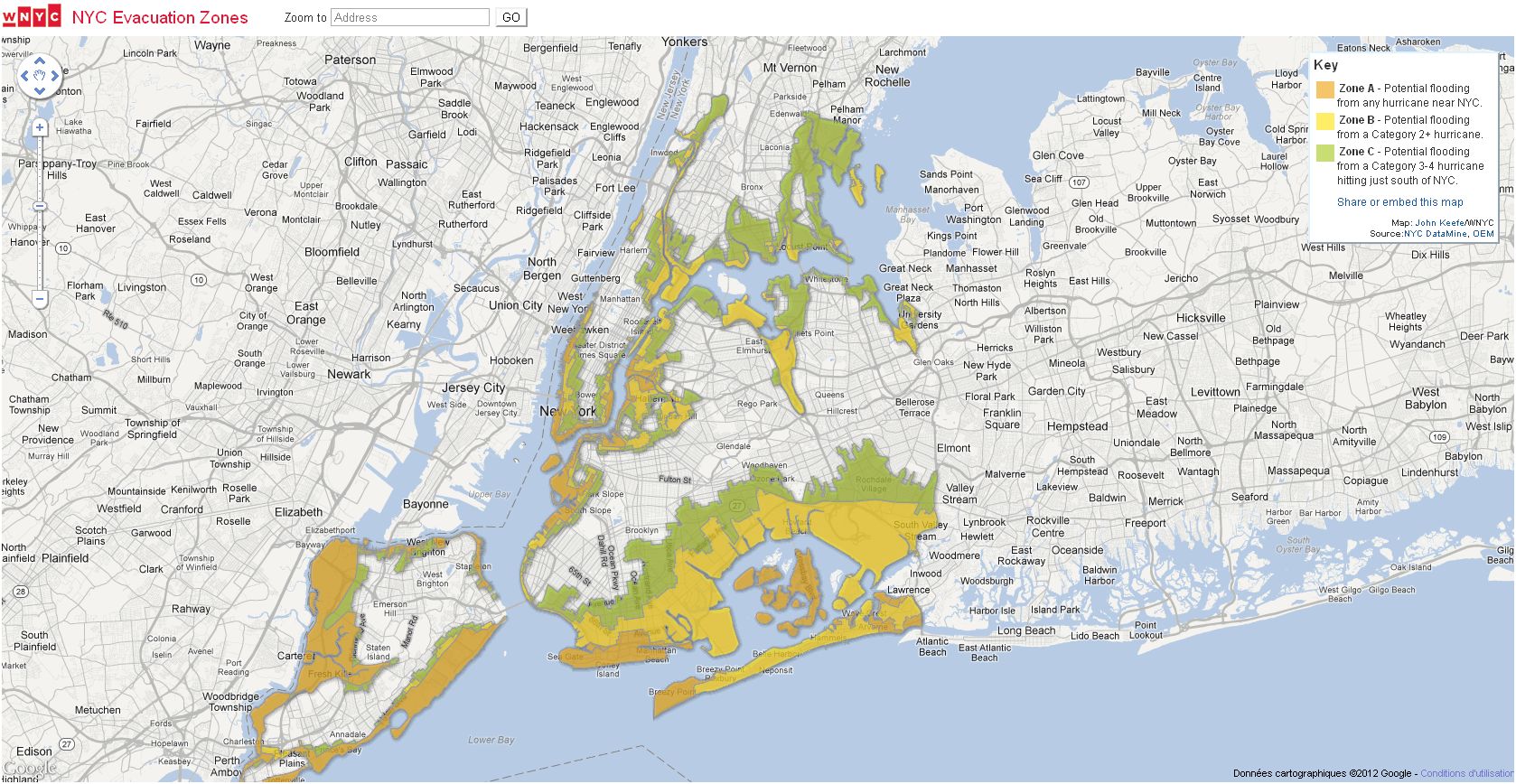
Un exemple d'utilisation de Fusion Tables (source WNYC)
Niveau de compétences : débutant.
S'utilise avec tout navigateur web.
En savoir plus : Google Fusion Tables
5 - Impure : un peu comme un Yahoo Pipes
Impure est une sorte de « Yahoo Pipes » adapté à la visualisation de données, conçu pour créer de nombreux types de représentations graphiques très peaufinées en utilisant un espace de travail de type « drag and drop ». Le service inclut une bibliothèque d'objets et de méthodes. Et, comme avec Yahoo Pipes, il permet de cliquer et déplacer pour connecter des modules de façon à ce que les « sorties » (output) de l'une deviennent les « entrées » (input) d'une autre. L'outil a été développé par la société d'analyse espagnole Bestiario.
Impure présente l'intérêt d'offrir une interface très visuelle pour préparer les représentations graphiques, ce qui n'est pas aussi fréquent qu'on pourrait s'y attendre. Il offre une interface élégante et de nombreux modules, dont quelques API (interfaces de programmation) destinées à extraire des données du Web.
On peut chercher par mots-clés (numeric, tables, nodes, geometry, map) ses nombreux types de visualisation. Et bien qu'il sauvegarde votre espace de travail sur le Web, il est possible de copier et conserver le code localement, afin de sauvegarder son travail et de mettre à jour ses propres bibliothèques de code.
Attention, les utilisateurs d'Impure devront faire un effort d'apprentissage malgré les fonctionnalités drag and drop. La documentation est quelquefois détaillée, mais pas toujours. Une fois que l'espace de travail est sauvegardé, il devient public sur le web, bien qu'il soit difficile de le retrouver sans l'URL. 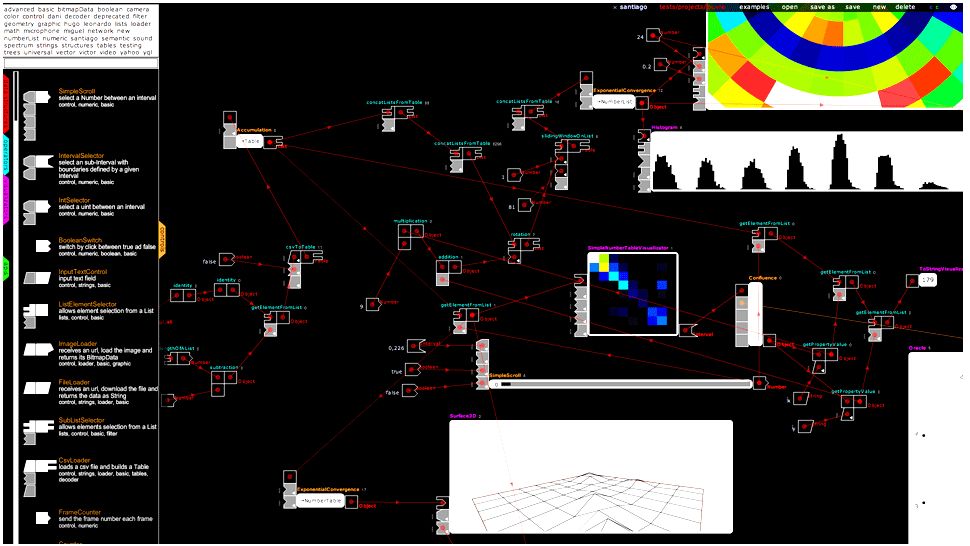
Impure (cliquer ici pour agrandir l'image)
Niveau de compétences : intermédiaire.
Fonctionne sur tout navigateur.
En savoir plus : sur Impure
[[page]]
6 - Many Eyes : facile d'accès et bien documenté
Le projet Many Eyes d'IBM est l'un des pionniers de la visualisation de données sur le web. Il est très facile à utiliser et très bien documenté, incluant des suggestions sur le type de représentations qu'il convient d'utiliser suivant les cas. Many Eyes comprend plus d'une douzaine d'options de rendu, depuis les graphiques sectoriels, jusqu'aux nuages de mots, en passant par les treemaps, les diagrammes relationnels, plots, ainsi que quelques cartes géographiques.
Il faudra ouvrir un compte gratuit pour mettre ses données en ligne. Le formatage est basique : pour la plupart des visualisations, les données doivent être dans un fichier texte avec séparation par tabulateurs, comportant des têtes de colonnes sur la première ligne. Les résultats offerts apparaissent bien plus sophistiqués que ce que l'on aurait pu attendre au regard des efforts déployés pour les créer. La liste de visualisations possible s'accompagne d'explications pour déterminer celles qui sont les plus appropriées suivant le contexte.
Inconvénient : vos jeux de données apparaissent publiquement sur le site Many Eyes et peuvent être facilement téléchargées, partagées, republiées et commentées par d'autres, ainsi que le projet soutenu par IBM encourage à le faire. Autre limite : la personnalisation est limitée, de même que la taille du fichier, qui ne peut pas dépasser 5 Mo.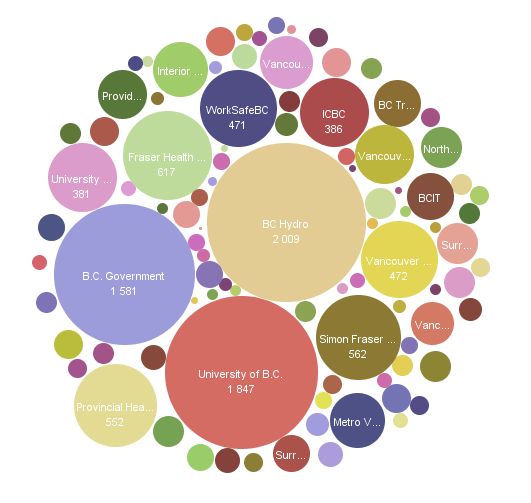
Many Eyes (cliquer ici pour agrandir l'image)
Niveau de compétences : débutants.
Fonctionne sur les navigateurs Java et ceux pouvant afficher en Flash.
En savoir plus : sur Many Eyes
7 - Tableau Public : personnalisable et interactif
Transforme les données en diverses visualisations, simples ou plus complexes. Les champs peuvent être glissés/déplacés sur l'espace de travail et le logiciel peut alors suggérer un type de visualisation, puis personnaliser tous les éléments : étiquettes, infobulles, taille, filtres interactifs, légendes... L'un des intérêts de l'outil réside dans les différentes façons d'afficher des données interactives sur lesquelles un filtre de recherche peut agir sur de nombreux graphiques, diagrammes et cartes. Les tables sous-jacentes peuvent également être jointes. Et une fois que vous savez comment fonctionne le logiciel, le maniement de son interface « drag and drop » se fait bien plus rapidement que de coder en JavaScript ou en R. Ce qui incite à essayer davantage de scénarios avec les données. En outre, on peut facilement effectuer des calculs sur les données au sein du logiciel.
Dans cette version gratuite du logiciel de BI de Tableau Software, les données doivent résider sur le site de Tableau. La mise à jour vers la version desktop coûte environ 1 000 dollars. Par ailleurs, sans surprise, les fonctionnalités gratuites ont malgré tout un coût : le temps d'apprentissage comparé à, par exemple, Fusion Tables. Même avec l'interface drag and drop, cela prend plus d'une heure ou deux pour savoir se servir du logiciel, à moins de réaliser d'abord des graphiques simples.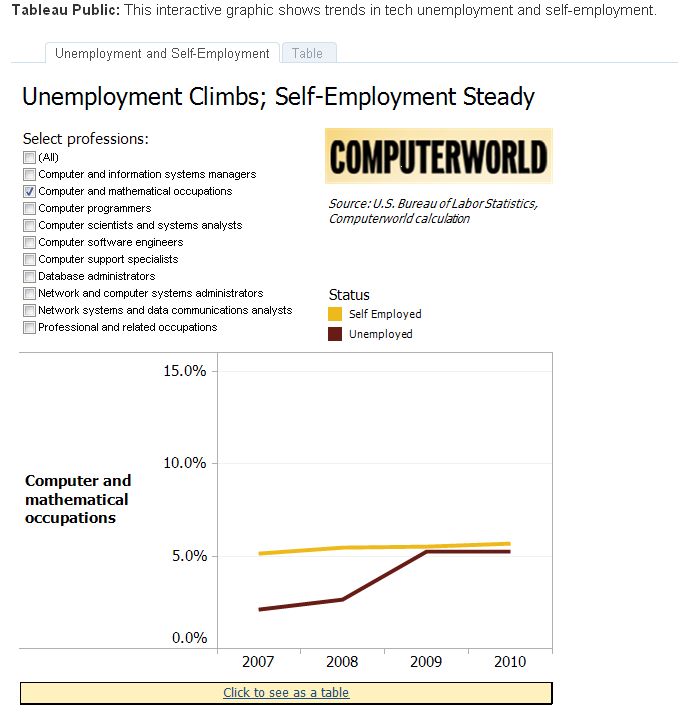
Tableau Public (cliquer ici pour agrandir l'image)
Niveau de compétences : débutant avancé ou intermédiaire.
Fonctionne sur Windows 7, Vista, XP, 2003, Server 2008 et 2003.
En savoir plus : quelques vidéos de formation
8 - VIDI : des graphiques exportables en HTML
Quoi que le site VIDI le présente comme un outil pour le système de gestion de contenus Drupal, les graphiques créés par l'assistant de visualisation du site peuvent être utilisés sur n'importe quelle page HTML sans recourir à Drupal. Une fois les données en ligne, on sélectionne le type de visualisation retenu, on personnalise un peu et le graphique est prêt à être utilisé via un code embarqué auto-généré (utilisant une balise iframe, pas de JavaScript, ni de Flash).
C'est à peu près aussi facile que Many Eyes, avec davantage d'options cartographiques et sans être obligé de rendre ses données publiques. Quelques écrans fournissent rapidement des explications sur chaque type de représentation graphique et on accède à différentes couleurs de personnalisation. La taille limite des fichiers monte à 30 Mo, soit six fois plus qu'avec Many Eyes.
VIDI, source Computerworld (cliquer ici pour agrandir l'image)
Niveau de compétences : débutants.
Fonctionne avec tout navigateur web.
En savoir plus : http://www.dataviz.org/
9 - Zoho Reports : pour les analyses métiers
L'un des plus orienté « analyse métier » de sa catégorie. Zoho Reports peut récupérer les données venant de différents formats de fichiers ou directement d'une base de données et les transformer en graphiques sectoriels, tableaux et tables pivots, autant de formats familiers aux utilisateurs de tableurs.
Il présente l'intérêt de pouvoir programmer des importations de données depuis des sources provenant du web. On peut faire des requêtes sur les données en utilisant SQL et les transformer en représentations graphiques. Le service permet de faire de la publication web et du partage. Il faudra toutefois disposer d'un compte payant si plus de deux utilisateurs doivent accéder aux données.
Inconvénient : les options de visualisation sont limitées. L'interaction de données avec le web peut être lente quelquefois. La taille des fichiers est limitée à 10 Mo.
Zoho Reports (cliquer ici pour agrandir l'image)
Niveau de compétences : débutants avancés.
Fonctionne sur tout navigateur.
En savoir plus : http://reports.zoho.com/ZDBSampleDatabases.cc
Pour lire la 2ème partie « 22 outils gratuits pour visualiser et analyser les données »
Cinq technologies Open Source pour 2012 (1ère partie)
L'année prochaine, si tout se passe comme prévu, Red Hat deviendra le premier éditeur Open Source à générer plus d'un milliard de dollars de chiffre d'affaires annuel. Cela constituera un tournant pour le monde de l'Open Source qui a longtemps considéré son approche du développement « communautaire » comme une alternative viable, voire supérieure, aux notions traditionnelles régissant l'écriture de logiciels. Jim Whitehurst, PDG de Red Hat, estime que l'on assiste à un changement fondamental sur l'origine de l'innovation. Pour lui, celle-ci est passée des laboratoires de quelques éditeurs vers l'Open Source où se déploient des efforts considérables.
De fait, l'Open Source a bousculé le monde du logiciel propriétaire ces dernières années, à mesure que Linux, le serveur web Apache, ou encore Perl, OpenOffice, Hadoop, GIMP et des dizaines d'autres programmes empiétaient sur le terrain de leurs équivalents commerciaux. Mais quels seront les poids lourds de demain ? Voici cinq projets à regarder de près en 2012. Ils pourraient constituer une base pour de nouvelles activités. Ou tout au moins séduire les développeurs et administrateurs en facilitant les façons de faire, ou en réduisant les coûts.
1 - Nginx, serveur web pour les sites à fort trafic :
Sur la décennie écoulée, le choix du serveur web a été relativement stable. On trouvait Apache sur la majorité d'entre eux tandis qu'Internet Information Services (IIS, ex Internet Information Server), de Microsoft, était à l'oeuvre sur les autres. Toutefois, au cours des dernières années, une troisième option est apparue avec Nginx (prononcez « engine-x »), en raison de la capacité de ce dernier à contrôler des trafics importants.
Nginx gère déjà 50 millions de noms de domaines, soit 10% de la totalité d'Internet, selon les estimations de ses développeurs. Il est particulièrement utilisé sur les sites web à fort trafic, tels que Facebook, Zappos, Groupon, Hulu, Dropbox et WordPress. Son créateur, Igor Sysoev, l'a conçu en 2004 pour gérer un grand nombre d'utilisateurs simultanés, jusqu'à 10 000 connexions par serveur. Son architecture est assez réduite, selon Andrew Alexeev, co-fondateur de la société, qui propose une version commerciale du produit.
L'année qui s'annonce devrait être bonne pour Nginx qui a récupéré 3 millions de dollars de différentes sociétés de capital risque, l'une d'elles étant soutenue par Michael Dell, le PDG de Dell. L'éditeur de Nginx a noué un partenariat pour fournir son serveur dans le package de Jet-Stream, un acteur de la diffusion de contenus (content delivery network). Il travaille aussi avec Amazon pour adapter son logiciel au service de cloud AWS.
En dehors du recours à Nginx dans les opérations web de grande ampleur, Andrew Alexeev voit l'utilisation de son serveur sur le marché du cloud computing et des services partagés. « C'est là où nous pourrons apporter le plus de bénéfice », estime-t-il en indiquant que la prochaine version importante, attendue en 2012, sera plus flexible pour les environnements d'hébergement partagés. Il précise qu'elle affrontera mieux les attaques distribuées en déni de services (DDoS) et comportera des fonctions de sécurité supplémentaires.
OpenStack, page 2
Stig, page 3
2e partie : Linux Mint et GlusterFS
[[page]]
2 - Le projet de cloud OpenStack :
Le projet OpenStack est arrivé relativement tard dans la sphère du cloud computing, mais il a apporté une fonctionnalité indispensable : l'extensibilité. « Nous ne parlons pas ici de gérer un cloud de 100 ou 1 000 serveurs, mais des dizaines de milliers de serveurs », explique Jonathan Bryce, qui préside le bureau du projet. Selon lui, les autres choix actuellement disponibles ne prennent pas véritablement en compte cette échelle.
Depuis son lancement en juillet 2010, OpenStack a rapidement gagné de nombreux soutiens de la part d'acteurs IT intéressés par le cloud, comme Hewlett-Packard, Intel et Dell. Les inconditionnels de cette brique IaaS (Infrastructure as a service) aiment à présenter leur travail comme le projet Open Source au développement le plus rapide, avec l'implication de plus de 140 entreprises et de 2 100 participants. Sous le nom de Dell OpenStack Cloud Solution, le Texan a lancé un package qui l'associe à ses serveurs et logiciels. HP a également lancé, en bêta, un service de cloud public utilisant cette technologie.
Le noyau de traitement d'OpenStack a été développé au centre de recherche Ames de la NASA, pour les besoins d'un cloud interne destiné à stocker de très importants volumes d'imagerie spatiale. A l'origine, les administrateurs de la NASA ont essayé d'utiliser la plateforme Eucalyptus, mais ils ont rencontré des limites à dimensionner le logiciel aux échelles requises, selon Chris Kemp, qui supervisa le développement du contrôleur de cloud OpenStack lorsqu'il était directeur informatique de NASA Ames.
Pour favoriser une plus large adoption, OpenStack a été complété d'autres fonctionnalités afin d'être mieux accepté par les entreprises, explique John Engates, directeur technique de l'hébergeur Rackspace. L'un des projets, appelé Keystone, permettra par exemple aux entreprises d'intégrer OpenStack avec leurs systèmes de gestion des identités, basés sur Active Directory, de Microsoft, ou sur d'autres annuaires LDAP. De la même façon, les développeurs travaillent aussi sur un portail pour les logiciels. Rackspace, qui a d'abord collaboré avec la NASA pour packager OpenStack pour un usage général, poursuit par ailleurs le projet de façon séparé et indépendante, en espérant constituer ainsi une option attractive pour davantage de fournisseurs de cloud.
« 2011 a été l'année de construction pour la base du produit, mais je pense que 2012 sera celle où nous commencerons vraiment à utiliser cette base pour de nombreux clouds publics et privés », estime le directeur technique de Rackspace.
Nginx, page 1
Stig, page 3
2e partie : Linux Mint et GlusterFS
[[page]]
3 - Stig, une base de données orientée graphe
Au cours de l'année écoulée, le recours à des bases de données non relationnelles s'est développé de façon importante, avec des solutions comme Cassandra, MongoDB, CouchDB et bien d'autres encore. Toutefois, lors de la conférence NoSQL Now, en août, il fut beaucoup question d'une base qui n'était pas encore disponible : Stig. Avec un peu de chance, on devrait la voir en 2012.
Stig est spécialement conçue pour prendre en charge les traitements liés aux sites de médias sociaux, expliquent ceux qui y travaillent. Elle a été créée au sein du réseau social Tagged par le développeur Jason Lucas. Celui-ci présente sa technologie comme une base de données distribuée orientée graphe. Elle a vocation à supporter les applications web de type social qui sont fortement interactives. L'architecture de stockage des données permet d'effectuer des recherches déductives, à travers lesquelles les utilisateurs et les applications peuvent prendre en compte les connexions entre des éléments d'information disparates. Parce qu'elle a été écrite, en partie, avec le langage de programmation fonctionnel Haskell, elle peut répartir facilement sa charge de travail entre plusieurs serveurs.
La base Stig reste encore un peu mystérieuse, puisqu'elle n'est pas sortie. Mais les observateurs prédisent qu'elle pourrait jouer un rôle dans les réseaux sociaux et les applications qui exploitent une large étendue de données. Par nature, les besoins des services liés aux réseaux sociaux sont différents d'autres catégories de traitements et ils tireraient profit d'une base qui leur soit ajustée, explique Jason Lucas. « Dans ce domaine, vous ne pouvez pas apporter de réponse pertinente si votre service n'est pas capable de s'étendre à l'échelle planétaire ».
Stig fonctionne actuellement sur un serveur au sein du réseau social Tagged, mais la société pense étendre son utilisation jusqu'à en faire sa seule base de données. Au départ, les développeurs prévoyaient une sortie en décembre, mais celle-ci a été repoussée à 2012. « Ce que j'ai pu en voir m'a semblé très intéressant », a indiqué Dan McCreary, un architecte en solutions sémantiques pour la société de conseil Kelly-McCreary & Associates. Il a apprécié l'architecture basée sur un langage fonctionnel qui devrait faciliter le déploiement de la base de données à travers plusieurs serveurs.
Nginx, page 1
OpenStack, page 2
2e partie : Linux Mint et GlusterFS
Applications JavaScript et HTML 5 : Wakanda en bêta publique
Plateforme de développement Open Source émanant de l'éditeur français 4D, Wakanda est destinée à la conception d'applications web « orientées modèles », écrites en JavaScript et HTML 5. Elle vient d'être proposée au téléchargement dans une version bêta publique.
Wakanda se compose de trois éléments : un environnement de développement graphique Studio, un serveur http multithread comportant un datastore NoSQL et un framework intégré avec le serveur http et le stockage des données. Cela permet de n'être pas « contraint d'assembler des briques séparées comme c'est typiquement le cas avec les solutions Ajax, PHP, MySQL, Apache », explique dans un communiqué Laurent Ribardière, directeur technique de 4D et créateur de Wakanda.
Retours d'expérience souhaités
Le framework est disponible sous licence GNU GPLv3. Durant la période de bêta test, 4D indique qu'il sollicitera le retour d'expérience des premiers utilisateurs de la plateforme pour faire évoluer le produit.
Le datastore objet NoSQL communique nativement en REST/HTTP et en SSJS (Server-side JavaScript). L'environnement de développement Wakanda Studio propose une interface graphique pour le design de l'application (en Wysiwyg) et pour le modèle de classes. Celle-ci dispose d'un accès direct au modèle conceptuel.
4D précise que le modèle d'application est également accessible via des frameworks Ajax tels que Dojo, YUI et DHTMLX, des applications mobiles natives sous iOS et Android ou des serveurs PHP, .Net, Java, Python, NodeJS. Wakanda Server fonctionne avec Windows (à partir de Vista), Mac OS (à partir de Mac OS X 10.6) et Linux Ubuntu (à partir de la 10.4). Wakanda Studio s'utilise sous Windows et Mac OS.
Google App Engine adopte la réplication et la modularité des instances
La dernière version du SDK de Google pour la plateforme cloud App Engine inclut le service de réplication de données, baptisé High-Replication Datastore (HRD). Une version expérimentale de ce service avait été publiée en janvier 2011. Au bout de 6 mois, Google a constaté des problèmes de fiabilité dans les options standard de stockage. L'éditeur a donc attendu de résoudre ces difficultés pour l'intégrer dans son kit de développement.
Avec HRD, les données sont répliquées sur plusieurs datacenters. Cette offre, selon Google, accorde le plus haut niveau de disponibilité des données, mais cela se fait au prix d'une latence plus élevée en raison de la propagation des données. L'éditeur estime qu'un des avantages de HRD est que les applications demeurent entièrement disponibles lors de périodes de maintenances, mais aussi en cas de problèmes imprévus comme des pannes de courant.
Modularité des instances et API expérimentales
Parmi les autres apports du SDK, Google a introduit deux classes d'instance supplémentaires pour les applications plus gourmandes en puissance CPU et mémoire. Un troisième type sera modulaire. Par défaut, elle utilisera une instance basique comprenant 128 Go de Ram et 600 MHz de CPU. Les entreprises pourront faire évoluer les ressources de leur serveur virtuel en payant un complément.
La firme de Mountain View a intégré aussi des API expérimentales. L'API Conversion permet aux utilisateurs de convertir du HTML en PDF, d'extraire du texte au sein d'image en utilisant un OCR. Logs Reader donne, quant à elle, la possibilité de créer des rapports, de recueillir des statistiques, et d'analyser des requêtes.
Le SDK est disponible pour Java et Python, et les deux sont en version 1.6.1. Ils peuvent être téléchargés sur le site de Google.
Base de données : SAP vise désormais la place de numéro 2
Le projet HANA, dont la paternité revient au fondateur de SAP, Hasso Plattner, et au CTO, Vishal Sikka, a été initialement présenté au milieu de l'année 2010 comme une plateforme permettant d'exécuter des charges de travail analytique beaucoup plus rapidement qu'avec les bases de données traditionnelles. Selon SAP, ce mode de fonctionnement où le système inscrit les données qu'il doit traiter en RAM, au lieu de les lire sur les disques, permet des gains en performance significatifs, voire très impressionnants.
Mais, rapidement, SAP a commencé à évoquer la capacité de HANA à gérer des charges de travail transactionnelles dans le domaine de l'ERP (Enterprise Resource Planning) et dans d'autres types d'applications, le positionnant comme une alternative éventuelle à certains produits, notamment la base de données phare d'Oracle. « C'est une opportunité très stimulante, parce qu'elle ouvre sur la possibilité de développer des applications totalement nouvelles », a déclaré Vishal Sikka à la keynote qu'il a donné à l'Influencer Summit de Boston. Sur une diapositive, il a montré la future pile logicielle basée sur HANA. À la base de la pile se trouvent HANA et les services d'infrastructure et de gestion du cycle de vie associés. Viennent ensuite les services d'applications, puis ABAP et les services de la plateforme Java, surmontés par les environnements de développement, et enfin les applications construites par SAP et celles des vendeurs tiers.
SAP bientôt numéro 2 dans les SGBD ?
SAP trace aussi d'autres perspectives, annonçant une série d'initiatives en relation avec HANA de la part de vendeurs de middleware et d'analytiques comme Tibco, du fournisseur d'ERP UFIDA, du vendeur de visualisation de données BI (business intelligence) Tableau and Jive Software, connu pour ses solutions de réseau social pour l'entreprise. « Dorénavant, SAP entend disposer d'un « écosystème tout à fait ouvert » pour HANA, » a indiqué Vishal Sikka. Cela paraît logique, bien sûr, étant donné que HANA est un produit relativement nouveau qui a beaucoup de choses à rattraper pour se mettre au niveau d'Oracle et d'autres. Cela n'a pas empêché un autre responsable de SAP de faire une prédiction très optimiste, mardi, après la keynote de Vishal Sikka. « Retenez-ce que je vais vous dire : en 2015, nous serons le deuxième vendeur de bases de données sur le marché, » a déclaré Steve Lucas, Global General Manager Business analytics and technology. « Je sais qui nous devons dépasser. Ce ne sont pas de petits acteurs. Il va nous falloir quelques années et beaucoup d'ingénierie pour y arriver. Mais nous le ferons. »
« SAP va également chercher à conclure des partenariats avec des éditeurs de logiciels qui intégreront HANA dans leurs produits, » a ajouté Steve Lucas. Une autre bonne manière pour SAP d'avancer vers son objectif serait d'ajouter le support HANA pour son logiciel phare Business Suite, dont de nombreuses mises en oeuvre fonctionnent sur Oracle. « Ce travail est en cours, et comme aucune date d'achèvement n'a été fixée, on peut s'attendre à une mise à jour pour la conférence Sapphire de l'année prochaine, » a déclaré Sethu Meenakshisundaram, CTO adjoint de SAP. « C'est un projet de première importance et nous avançons. » SAP n'a pas encore décidé « si elle vendra aussi HANA comme base de données autonome, » a encore déclaré Vishal Sikka dans une interview.
Déjà 100 millions de dollars de vente pour HANA
« En attendant, SAP a récemment franchi une étape avec HANA, dépassant les 100 millions de dollars de ventes, » comme l'a révélé le directeur technique de SAP au cours de sa keynote. HANA est vendu sous forme d'appliance par un certain nombre de fabricants. « Les 100 millions de dollars ne prennent en compte que les revenus de licence du logiciel de SAP, » a aussi précisé Vishal Sikka dans son interview. « Autre signe du succès de HANA, dans toutes les régions du monde, les clients ont racheté d'autres produits intégrant le système, » a ajouté le dirigeant. « CSC, l'un des leaders mondiaux dans le conseil, l'intégration de solutions d'entreprise et l'externalisation devrait adopter HANA, » a déclaré David McCue, vice-président et CIO de CSC, dans une interview. « La première instance de production concernera environ 1 téraoctet de données, mais CSC réfléchit, encore à quel type d'usage elle sera affectée, » a-t-il ajouté.
« HANA est un produit jeune, mais c'est aussi une solution viable, » a encore déclaré le CIO de CSC. « Nous sommes suffisamment confiants pour l'acheter, et nous réaliserons plusieurs mises en oeuvre pour le compte de nos clients, » a-t-il ajouté. Ce dernier a aussi donné un point de vue mesuré sur le projet à long terme envisagé par SAP pour HANA. « S'il est matériellement réalisé, le produit aura un très bon retour, » a-t-il estimé. « Sans aucun doute, HANA a montré dans sa version actuelle qu'il avait assez de ressources pour qu'on s'y intéresse. Mais comme toute prospective à long terme, celle-ci pourrait être contredite par les événements. »
[[page]]
Hier à Boston, SAP a également abordé la question de sa stratégie logicielle dans le cloud computing, récemment agitée par le rachat de SuccessFactors pour 3,4 milliards de dollars. C'est le PDG du vendeur de logiciels de gestion des ressources humaines à la demande, Lars Dalgaard, qui sera placé à tête de l'activité cloud de SAP une fois la transaction achevée. Cette acquisition intervient après plusieurs années pendant lesquelles SAP s'est employé à peaufiner précisément son approche du logiciel dans le cloud. Cela n'a pas été une mince affaire pour un éditeur comme SAP, dépendant du modèle de logiciel sur site et du flux de revenus prévisibles et lucratifs rapportés par le renouvellement perpétuel des licences et les services de maintenance. Ce concept a du être bouleversé et remplacé par un système d'abonnement, devenu le standard du cloud.
« Mais SAP a encore le temps de voir venir, et l'expérience de SuccessFactors va être un atout majeur, » a déclaré Jim Hagemann Snabe, le co-CEO, lors d'un discours liminaire. « 80% des clients importants n'ont pas fait leur choix de stratégie pour le cloud, et pensent encore en terme de cloud privé. On voit aussi que les applications de pointe sont encore confiées à des services de cloud public. » « La combinaison de nos actifs et de SuccessFactors transforme une entreprise qui a essayé de bien faire les choses... en une entreprise qui va croitre rapidement dans le monde, » a-t-il ajouté. « Nous passons aussi d'un mode défensif, à un mode offensif. »
(...)| < Les 10 documents précédents | Les 10 documents suivants > |