Flux RSS
Décisionnel
626 documents trouvés, affichage des résultats 201 à 210.
| < Les 10 documents précédents | Les 10 documents suivants > |
(22/06/2010 11:07:46)
Applications de BI : des outils spécifiques perdurent, montre Forrester
La plupart des éditeurs de logiciels de Business Intelligence (BI) ont enregistré des croissances à deux chiffres en 2009. La tendance se poursuit en 2010, confirme Forrester. Le cabinet d'analyse en profite pour rappeler que, sur ce marché en rapide évolution, les fournisseurs doivent prendre en compte les tendances qui émergent. Dans une étude récemment publiée, l'analyste Holger Kisker distingue, d'une part, les avancées technologiques, telles que l'analyse prédictive ou textuelle, et d'autre part, les évolutions métiers et les nouvelles façons d'utiliser les solutions BI. C'est la combinaison de ces deux dimensions qui permettront aux éditeurs les plus en pointe de se détacher de leurs concurrents dans les années qui viennent.
17% utilisent des développements spécifiques
Entre septembre et novembre 2009, Forrester a sondé un peu plus de 2 100 responsables informatiques et décisionnaires sur les investissements technologiques, sur les priorités qui guident leurs dépenses IT, aux Etats-Unis, au Canada, en France, en Allemagne et au Royaume-Uni. Une partie d'entre eux (500 environ) a été questionnée sur les principaux éditeurs de logiciels BI vers lesquels ils se tournent. Les réponses font d'emblée apparaître que 17% des applications de BI utilisées globalement ont été développées de façon spécifique, en interne ou par un prestataire. Un pourcentage qui monte jusqu'à 30% chez les responsables français interrogés.
Pour le reste des applications utilisées, les fournisseurs le plus souvent cités sont SAP/Business Objects (20%), IBM (17%) et Oracle (14%). Les autres acteurs représentent 25% des réponses, mais seuls quatre dépassent les 1% : SAS, Information Builders, Actuate (2%) et Microstrategy (3%). La plupart des entreprises ont plusieurs fournisseurs d'outils BI et 7% n'en connaissent pas le nom. Attention toutefois à ne pas comparer ces classements aux parts de marché des différents fournisseurs, calculées en fonction des ventes réalisées sur une année donnée. Microsoft, par exemple, n'apparaît pas dans les réponses de l'étude Forrester car SQL Server, Excel ou SharePoint ne sont pas toujours vus par les répondants comme des outils décisionnels.
Cliquer ici pour agrandir le graphique
Parmi les entreprises françaises sondées, c'est IBM qui vient en tête des éditeurs listés (22%), suivi de SAP (15%) et d'Oracle (7%).
La gestion de l'information en tête des priorités
Forrester a également interrogé les responsables IT et décisionnaires sur les investissements qu'ils prévoient de faire. 84% se disent très intéressés par les logiciels de gestion de l'information et des connaissances. Dans l'ordre d'intérêt, ces outils arrivent en 3e position, derrière les solutions de comptabilité/finance et de gestion de la relation client (CRM). En creusant la question, il apparaît que 54% des 920 entreprises sondées ont déjà mis en place des logiciels de Business Intelligence : 30% qui sont en cours de déploiement et 24% qui en étendent le périmètre. La proportion est moins élevée sur l'échantillon de responsables français interrogés : 27% exploitent déjà des logiciels de BI (17% en déploiement, 10% en cours d'évolution).
Par ailleurs, si globalement 25% des entreprises sondées par Forrester ont un projet de BI sur 2010 ou pour début 2011, ils ne sont que 18% à le dire parmi les responsables français.
(...)(18/06/2010 16:19:01)Forum CXP : où va l'informatique décisionnelle ?
Si certains témoins d'entreprises étaient pour le moins peu expérimentés (« nous déployons demain » a ainsi avoué l'un), l'intérêt de la manifestation résidait surtout dans les analyses de marchés, le plus souvent en forme de « bilan et perspectives ».
La BI se banalise
Le décisionnel a ainsi fait l'objet d'une session animée par Laurence Dubrovin et Laëtitia Bardoul en présence d'éditeurs (Tibco, Prelytis, Cognos/IBM et Reportive) et de clients (Egamo, Takasago et Renault). Sans concession, les intervenants ont admis, sur la base d'études assez anciennes du Gartner notamment, que 60% des projets de décisionnel étaient des échecs et 20% n'étaient pas utilisés régulièrement par leurs destinataires. La tendance, du coup, est aujourd'hui à des projets plus légers et moins chers, développés plus rapidement avec une plus grande réactivité, bref en méthodes agiles, avec des progiciels de nouvelle génération. Ceux-ci, pour éviter le recours à un ETL, sont de plus en plus nombreux à aller piocher directement dans les données de production.
Les projets décisionnels ont aussi migré en terme de population cible : des seules DG et DAF, ils visent désormais tous les métiers. Chaque responsable métier a en effet besoin de ses propres indicateurs. Les solutions sont, de ce fait, également de plus en plus dédiées et pré-paramétrées soit pour un métier soit pour un secteur.
La querelle des anciens et des modernes n'aura pas lieu
La tendance est également à disposer de produits capables d'être pris en main par les utilisateurs eux-mêmes facilement, y compris pour créer des états. Globalement, les « vieilles » solutions (comme Cognos, Hyperion...) ont tendance, dans leurs versions récentes, à se rapprocher de la convivialité des solutions « légères » (Qliktech...). En retour, ces dernières voient leurs fonctionnalités s'accroître au fil du temps. La dichotomie n'est plus, par conséquent, aussi évidente qu'il y a quelques années.
Les recommandations des analystes du CXP étaient attendues : comme dans tous les projets informatiques, il convient de d'abord fixer les objectifs métier avant de se préoccuper d'un choix technique ; les utilisateurs doivent être impliqués dès l'origine du projet ; et, enfin, la qualité des données doit être soignée. Ce dernier sujet est visiblement le point délicat qui reste à traiter en matière de décisionnel.
[[page]]
Malgré tout, l'implication voulue des métiers n'est pas toujours si évidente. « Le temps nécessaire à un tel projet est toujours sous-estimé et, dans des équipes toujours réduites d'ajouter un pilotage de projet informatique au travail normal » a ainsi avoué Nicolas Demont, DG d'Egamo, une filiale de gestion d'actifs de la MGEN. Sur le plan technique, cette société de 14 personnes (pour deux milliards d'euros gérés) a cependant eu juste besoin d'un stagiaire en informatique pour la mise en oeuvre du premier projet, en plus du prestataire et du pilotage métier. Or ce premier projet a souligné le besoin de restructurer et d'améliorer la qualité des données.
La base de données SQL Server de consolidation a été paramétré avec des procédures stockées pour avoir des données propres calculées à partir des données externes. De plus, via Spotfire de Tibco, les clients externes confiant leurs actifs à l'entreprise peuvent suivre en détail leurs comptes via un accès extranet. Les données traitées dans le décisionnel peuvent également être « redescendues » dans les sources mais avec des contrôles en fonction du profil de la personne ayant entré l'information. Enfin, les modèles d'analyses ne sont pas conçus par chaque utilisateur. Dans ce secteur particulier de la gestion d'actif, il est essentiel que ces modèles soient communs à toute l'entreprise et donc validés par la direction générale.
A l'inverse, Eric Chavaset, directeur logistique du producteur de parfums et fragrances (alimentaires et non-alimentaires) Takasago, a précisément choisi Prelytis pour la facilité pour l'utilisateur final à concevoir des états. En l'occurrence, il s'agissait de pouvoir suivre la rentabilité de projets aux multiples intervenants. Mais il a averti : « les deux tiers du projet ont consisté à rendre les données fiables ».
[[page]]
Le décisionnel servant à décider, il doit aussi servir à prévoir. Les systèmes prédictifs constituent cependant une branche séparée, avec des outils spécifiques (SPSS/IBM, certains modules de MicroStrategy, de SAS ou d'Information Builders...). « Les systèmes prédictifs, ce sont avant tout des mathématiques et des statistiques » a martelé Christian Carolin, analyste du CXP.
Ces systèmes reposent sur deux types d'approches : soit par modèles, soit par méthodes statistiques. Les modèles peuvent être soit formels (principe des « systèmes experts », principe des scorings de risques dans les établissements de crédit par exemple), soit connexionnistes (mise en relation de données selon un principe de réseau neuronal avec auto-apprentissage). Les méthodes statistiques, quand à elles, peuvent être soit non-supervisées (des phénomènes atypiques sont mis en valeur sans recherches pré-déterminées) soit supervisées (avec des questions préalables). Christian Carolin tempère cependant : « dans les faits, les produits sont souvent mixtes ».
Mais là encore, la qualité des données est au coeur de la problématique. Christian Carolin donne ainsi cet exemple simple : « si un système met une date par défaut pour la naissance si celle-ci n'est pas renseignée, travailler sur les dates sans précautions devient un non-sens. »
Avec VectorWise, Ingres affûte sa base pour les gros volumes
En s'appuyant sur un projet de recherche mené par l'Institut néerlandais CWI de recherche en informatique, l'éditeur de logiciels en Open Source Ingres vient de lancer une base de données spécifiquement conçue pour traiter les très gros volumes. C'est la préoccupation désormais commune de tous les spécialistes de la gestion de données, bloqués par les capacités des SGBD relationnels lorsqu'il s'agit d'analyser un nombre toujours croissant d'informations.
La technologie mise au point par VectorWise (émanation du CWI) est basée sur un moteur de requête qui tire parti des dernières générations de mémoires et de processeurs. Celui-ci est combiné à un stockage en colonnes, mode d'organisation désormais plébiscité pour optimiser les performances de traitement sur plusieurs téraoctets de données. Des performances atteintes sans qu'il soit nécessaire de mettre en place un système massivement parallèle à la configuration complexe, assure VectorWise. Les premiers benchmarks ont été fait sur une plateforme équipée de processeurs Xeon 5500 (Nehalem).
La base de données Ingres VectorWise peut être téléchargée gratuitement pour test. 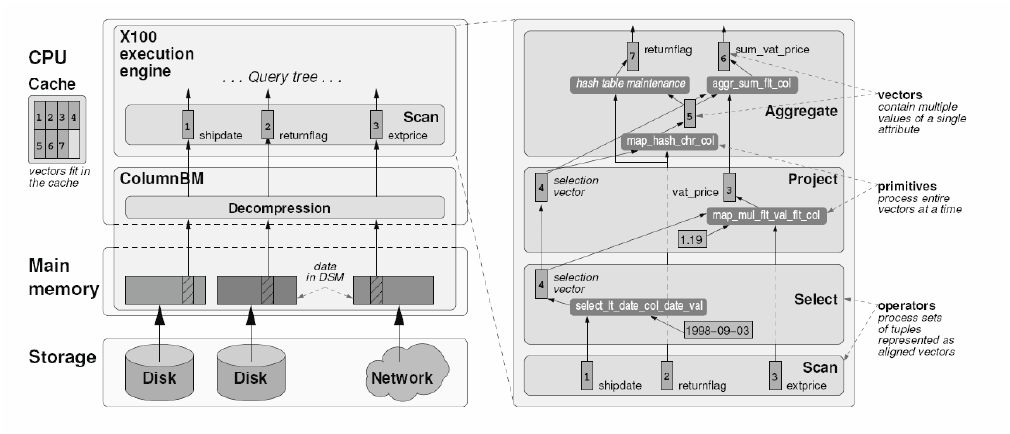
Cliquer ici pour agrandir l'image
En savoir plus :
- Livre blanc sur Ingres/VectorWise
- Télécharger Ingres/vectorWise
«L'effort de recherche de SAP est très important comparé aux ratios habituels»
Basé en France, à Levallois Perret, Hervé Couturier est directement rattaché au directeur technique de la société, Vishal Sikka (basé à Palo Alto), sous la responsabilité de Jim Hagemann Snabe, le co-PDG qui supervise le développement des produits.
LeMondeInformatique.fr : Depuis l'automne 2008, vous pilotez les équipes de développeurs travaillant sur le portefeuille d'applications Business Objects et sur la plateforme d'intégration SAP NetWeaver. Qu'est-ce qui va changer avec vos nouvelles attributions ?
Hervé Couturier, vice-président exécutif Technology group de SAP : Exception faite des couches basses de NetWeaver, plus précisément de la partie serveur d'applications que je ne superviserai plus, le périmètre de mes attributions est maintenu. Les équipes de développement de Business Objects et des autres couches de NetWeaver restent sous ma responsabilité. Mais j'ai récupéré en plus la partie recherche qui rassemble à peu près 450 personnes. C'est un effectif très important quand on le compare aux ratios habituels. Chez Business Objects, nous avions trois personnes dans ce domaine pour un effectif total de plus de 6 000 personnes. Là, nous sommes 450 alors que SAP compte 48 000 collaborateurs. Il s'agit donc d'un très gros effort de recherche.
Malgré cette prise de fonction sur la recherche, vous restez donc dans l'opérationnel ?
J'ai une position assez unique car je crois que c'est la première fois que l'on a quelqu'un qui est, en même temps, responsable de la recherche et de la livraison de logiciels. WebIntelligence, Explorer, Crystal Reports... sont des produits que je dois livrer pour le portefeuille d'applications décisionnelles, mais également Composition Environment, ou encore Process Integration, sur NetWeaver. Et je couvre en plus, maintenant, la partie recherche. J'ai donc vraiment un pied dans les deux mondes.
Avant sa restructuration en février dernier, SAP s'était vu reprocher de ne pas suffisamment innover. Depuis, l'innovation est devenu l'un des mots d'ordre des deux co-dirigeants, Jim Hagemann Snabe et Bill McDermott. Considérez-vous effectivement que la société péchait dans ce domaine ?
Je crois que c'est une des raisons, effectivement, pour lesquelles on m'a demandé de reprendre ce job. Parce qu'en toute humilité, je crois qu'avec les équipes que je pilote, nous avons eu tout de même de bons résultats dans la mise à disposition de nouveaux produits sur le marché. Au cours de deux dernières années, après l'acquisition par SAP, nous avons sorti BI OnDemand, BI sur mobile, Explorer et StreamWork, ce dernier ayant été livré en disponibilité générale en mai. Soit, en deux ans, dans le domaine des outils décisionnels et de collaboration, quatre nouveaux produits qui génèrent du revenu.
Lire la suite de cette interview dans la rubrique Entretien
Illustration : Hervé Couturier, vice-président exécutif Technology group de SAP (Crédit photo : SAP)
Boulanger unifie ses références catalogue
Surtout, il distribue plus de 20 000 références de produits sous 150 marques, avec une rotation parfois importante dans certains domaines où les produits changent souvent.
En lien avec SAP et les SI des fournisseurs
La gestion de son catalogue de produits et services virait au cauchemar devant les multiples applications devant utiliser ces données dans de nombreux contextes. Le groupe a donc décidé d'uniformiser et d'unifier un référentiel de produits dans une démarche de MDM (master data management) en utilisant InfoSphere Master Data Management Server for Product Information Management d'IBM.
En amont du système de MDM proprement dit, le référentiel-père est géré dans SAP : références produits, stocks, prix... En aval, le système dialogue avec les SI des fournisseurs pour les mises à jour. Enfin, des enrichissements manuels sont opérés au sein du MDM par des responsables appropriés (notamment en centrale d'achat). Les mises à jour sont répercutées du MDM vers les systèmes connectés et inversement
[[page]]
Des données intégrées et complétées à la main
Le référentiel des produits comporte les caractéristiques techniques et commerciales, des images, des informations structurées ou semi-structurées comme des notations sur une échelle de performance (x étoiles pour positionner une mention technique peu compréhensible du commun des clients)... Sur une famille de produits donné, des informations précisés et similaires sont renseignées, ce qui permet de générer aisément des tableaux de comparaison aussi bien en magasin que sur le web ou dans des documentations diverses.
Comme certains produits ne sont pas présentés en rayon (toutes les déclinaisons et toutes les couleurs d'une gamme par exemple), les tableaux de comparaison permettent également de mentionner aux clients ce qu'il est possible de leur vendre. Les mêmes données sont non seulement utilisées dans les différents SI commerciaux (magasins, web, etc.) mais aussi pour toute la communication (tracts, e-marketing, affiches, étiquettes...).
« Le traitement de l'information produit est devenu un processus métier comme un autre » spécifie Olivier Berrod, responsable informatique au pôle nouvelles technologies de Boulanger.Toutes les données produits ont donc été structurées et uniformisées. Leur traitement est donc plus simple et cohérent mais facilite également la réalisation de produits dérivés comme les tableaux de comparaison.
Le socle a été mis en place avec quelques pilotes en terme de familles de produits et d'applications de 2005 à 2007. En 2008, Boulanger a généralisé le déploiement, l'intégration multicanal ayant été intégrée en 2010. Dans les années à venir, Boulanger souhaite intégrer le rich media (des vidéos des produits par exemple) et les réseaux sociaux.
Le coût du projet n'a pas été mentionné.
Siemens applique le décisionnel au cycle de vie du produit
Siemens PLM Software ajoute une dimension décisionnelle à ses solutions de gestion du cycle de vie du développement des produits (PLM). Son infrastructure technologique HD-PLM vient compléter ses solutions NX (sortie dans sa version 7.5) et Teamcenter. Avec cette plateforme collaborative, l'éditeur a l'ambition de fournir à des décisionnaires, de façon visuelle, des informations concernant l'ensemble des phases du cycle de vie. Pour l'entreprise, cela implique de rassembler des données techniques, financières et logistiques, qui se trouvent stockées à différents endroits.
En réunissant l'ensemble des données relatives aux différentes étapes de conception et en les synthétisant dans un tableau de bord ou une visualisation graphique, les responsables disposeront d'une vue globale pour prendre les décisions les plus appropriées (en termes de choix de matériaux, de qualité, de coûts, de fournisseurs, etc.). Ils accéderont aux informations qui les concernent de façon contextuelle, mais en comprenant l'impact de leur choix sur les autres étapes du cycle de vie des produits. Les fonctions collaboratives serviront à communiquer avec les multiples intervenants.
L'environnement HD3D, déjà disponible dans la solution de PLM NX, depuis l'an dernier, présente les informations de manière graphique pour faciliter la prise de décision. Il fonctionne avec les outils disponibles dans NX pour valider les données par rapport au cahier des charges.
Comme IBM, Pentaho choisit Hadoop pour l'analyse des gros volumes de données
L'éditeur de logiciels décisionnels en Open Source Pentaho a indiqué qu'il prévoyait de livrer une suite décisionnelle complète s'appuyant sur le projet Apache Hadoop. IBM a lui-même confirmé la semaine dernière qu'il préparait un portefeuille de solutions et de services, Infosphere BigInsights, basé sur ce même projet Open Source conçu pour le traitement et l'analyse de très gros volumes de données. Les capacités apportées par Hadoop sont destinées à prendre en charge les flux de données considérables générés par exemple par les transactions bancaires et dans le secteur de l'assurance (avec l'objectif de détecter les fraudes), par les interactions sur Internet (sur les réseaux sociaux notamment) ou encore traités par les centres d'appels.
La suite Pentaho BI va d'abord fournir, pour les processus d'intégration de données, un environnement de conception visuel qui inclura la manipulation de fichiers Apache Hadoop. Cela permettra de concevoir et d'exécuter des processus ETL qui pourront impliquer à la fois des tâches Hadoop et non-Hadoop. A la suite de cette première brique, l'éditeur prévoit de livrer d'autres modules pour effectuer du reporting, des tableaux de bord et des analyses directement sur les données stockées sur un modèle Hadoop.
Pentaho propose aux entreprises intéressées de faire partie de son programme bêta.
Illustration : démo de Pentaho Enterprise intégré avec Hadoop
Microsoft admet ne pas communiquer sur toutes les failles de sécurité
« Microsoft communique un numéro de Common Vulnerabilities and Exposures (CVE) unique lorsque plusieurs failles sont concernées par la même vulnérabilité, visées par à un même vecteur d'attaque et une manoeuvre de contournement identique. Si l'ensemble de ces bugs partagent les mêmes propriétés, alors ils ne sont pas déclarés séparément, » a expliqué Mike Reavey. Cette absence de divulgation de correctifs par Microsoft a été dévoilée au début du mois par Core Security Technologies, laquelle a mis en évidence trois patchs « muets » dans les correctifs MS10-024 et MS10-028 qu'elle a décortiqué. Le bulletin de sécurité MS10-028 concernait une faille qui exposait l'utilisateur de Microsoft Visio à une attaque visant à saturer la mémoire tampon pour prendre le contrôle du système. A l'époque, l'éditeur n'avait pas signalé les autres bugs patchés en même temps au motif que «le vecteur d'attaque était exactement le même, et la gravité tout à fait identique. Du point de vue du client, la même solution a été appliquée, à savoir ne pas ouvrir de documents Visio à partir de sources non fiables », a déclaré Mike Reavey à Webwereld, filiale d'IDG, lors d'une interview.
Adobe a également gardé le silence sur certains correctifs de vulnérabilité. Pendant la conférence de Microsoft, Brad Arkin, responsable de la sécurité et de la confidentialité des produits chez Adobe, a admis que l'éditeur n'attribuait par de numéros CVE à des bogues que l'entreprise identifiait en interne. L'éditeur estime que ces mises à jour sont des « améliorations de code», a déclaré Brad Arkin. Les numéros CVE ne sont utilisés que pour les bugs activement exploités ou qui ont été signalés par des chercheurs extérieurs.
[[page]]
Le fait de se taire sur les mises à jour de sécurité n'est pas sans conséquence. Les éditeurs et les chercheurs en sécurité ont utilisé des chiffres CVE pour évaluer la sécurité des différents systèmes d'exploitation et des applications. Lors de la conférence de presse, Microsoft a montré une diapositive comparant le nombre de mises à jour de sécurité réalisées pour UbuntuLTS, Red Hat Enterprise Linux 4, OS X 10.4 ainsi que pour Windows Vista et Windows XP. Dans une autre diapositive, elle a montré celles effectuées pour SQL Server 2000, SQL Server 2005, comparée à une base de données anonyme concurrente.
Mike Reavey admet que cette comptabilité des failles de vulnérabilité est imparfaite, mais soutient que, comme outil de comparaison de base, cela a tout de même un sens. « On peut mesurer la sécurité de plusieurs manières. L'estimation de la vulnérabilité par le comptage des bugs en est un, et il n'est pas parfait. » La comparaison du nombre de vulnérabilités par ligne de code de logiciel est un autre indicateur.
S'il fait valoir que ces décomptes sont des moyens utiles pour comparer les produits entre fournisseurs, il a aussi minimisé l'enjeu du calcul des vulnérabilités, le qualifiant de méthode «comptable» qui a, selon lui, essentiellement pour effet de détourner les chercheurs de leur fonction de corriger les bugs. « Quand une faille est signalée, l'entreprise préfèrerait travailler à optimiser un outil de recherche capable de traiter 200 bogues liés. Techniquement, le code peut contenir 200 vulnérabilités, mais « en modifiant une ligne de code, vous perdez parfois la possibilité de corriger 200 problèmes potentiels par fuzzing. Est-ce que cela compte pour une ou pour 200 vulnérabilités ? Je ne sais pas vraiment. Mais si nous passons du temps à tenir une comptabilité exacte, c'est autant de temps en moins pour trouver la solution pour protéger nos clients, » a t-il déclaré.
(...)| < Les 10 documents précédents | Les 10 documents suivants > |