Une base de donnée Hadoop ready chez RainStor
Nous avons poursuivi la journée avec une visite chez RainStor, toujours à San Francisco. Fondée par des Britanniques, cette start-up propose une base de données SQL spécialement taillée pour le big data et le traitement décisionnel.
Multistructure, la solution de RainStor supporte nativement le système de fichiers HDFS, celui d'Hadoop. Rappelons qu'Hadoop est un agrégateur Open Source de données structurées et non structurées qui permettent d'analyser d'énormes volumes d'informations. En exécutant sa base de données nativement sur Hadoop, RainStor indique qu'il est possible d'interroger et d'analyser plus rapidement ces informations multi-structurées.

Mark Cusack, chief architect, et John Bantleman, CEO de RainStor
John Bandleman, le CEO de la compagnie, nous a expliqué qu'un des points forts de sa base est la compression drastique des données (dans un ratio de 40:1) et ce afin de réduire les coûts de possession du stockage. Second étage de la solution l'analytique avec une passerelle SQL et Oracle vers MapReduce. Cela concerne l'ensemble des données compressées, à la fois structurées et non structurées, en cours d'exécution les clusters HDFS.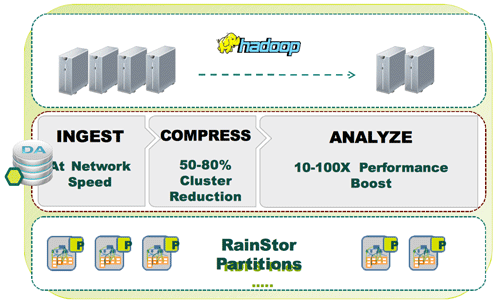
Deux baies de stockage 100% flash
Nous avons terminé notre journée avec une dernière rencontre avec Nimbus Data dans un hôtel de la Silicon Valley en état de siège. Mitt Romney organisait en effet un diner à 25 000 dollars le couvert pour lever des fonds pour sa campagne à l'investiture républicaine pour la prochaine élection présidentielle américaine. Cernés par les manifestants, les membres des services secrets et la police du comté de Redwood City, nous avons pu discuter avec Thomas Isakovitch, le CEO de Nimbus Data, de ses baies de stockage flash.
Silicon Valley 2012 : Ring 4 chez Scality, Big data chez RainStor et stockage flash chez Nimbus Data
0
Réaction
Newsletter LMI
Recevez notre newsletter comme plus de 50000 abonnés
Commentaire