")
A l’origine de la base de données open source Ignite (SQL et ACID), pilotée par la fondation Apache depuis 2014, GridGain surfe aujourd’hui sur la vague de la transformation numérique dans les entreprises qui plébiscitent les performances et la réactivité des plateformes in-memory. « Toute l’informatique se porte vers l’in-memory et SAP HANA est aujourd’hui le leader devant Oracle. Si ce sont eux [SAP] qui ont le plus d’applications, nous avons plus de fonctionnalités », nous a assuré le CEO de GridGain, Abe Kleinfeld. « Mais Hana reste devant nous car ils poussent toutes leurs applications sur Hana » poursuit le dirigeant. « Les entreprises qui construisent quelque chose de nouveau, regardent vers l’open source […] GridGain est comme un Hana open source à la différence que SAP Hana ne sera pas adoptée par les start-ups ou par les entreprises qui n'ont pas déjà investi dans la technologie SAP, parce qu'elle est propriétaire, haut de gamme et coûteuse », assène le dirigeant.
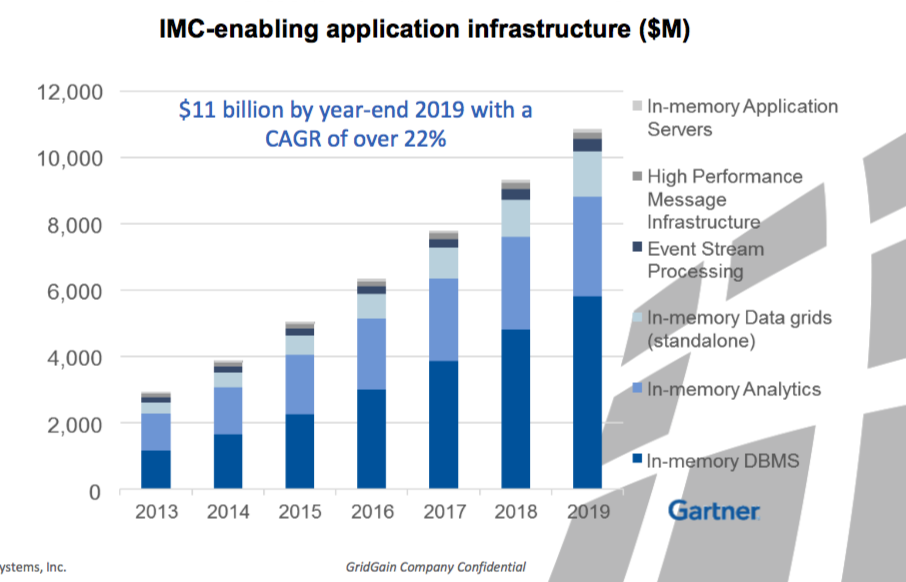
Selon le cabinet Gartner, le marché de l'in-memory connait une croissance continue. (crédit : Gartner)
« Une plateforme data in-memory n’est plus une option, mais une nécessité » vient compléter Noel Yuhanna, analyste principal chez Forrester, appelé en renfort dans un slide lors de la présentation d’Abe Kleinfeld. Comme le soutient Nikita Ivanov, fondateur et CTO de GridGain, l’heure est au fast data grâce à l’utilisation des technologies in-memory (RAM, flash et algorithmes de compression et de gestion des données les plus utilisées).
Un chiffre d'affaires en hausse
Reste ensuite à retenir la base de donnée in-memory la plus adaptée à ses besoins car la concurrence s’est étoffée ces dernières années avec Aerospike, que nous avons aussi rencontré en février dernier à Mountain View et le réveil d’Oracle et Microsoft. Aujourd’hui, GridGain qui ne se présente plus comme une start-up – l’entreprise a été fondée en 2007 et Ignite lancée en 2010 – annonce un chiffre d’affaire de 31 millions de dollars pour l’année précédente. Depuis notre dernière rencontre en juin 2017, les revenus ont donc doublé et le nombre d'employés est passé de 75 à 125 personnes. Les sanctions contre la Russie ont toutefois entrainé quelques difficultés comme nous a indiqué Nikita Ivanov. « Nous avons été obligés de bouger des employés ici, car il est de plus en plus difficile de faire des affaires en Russie ».
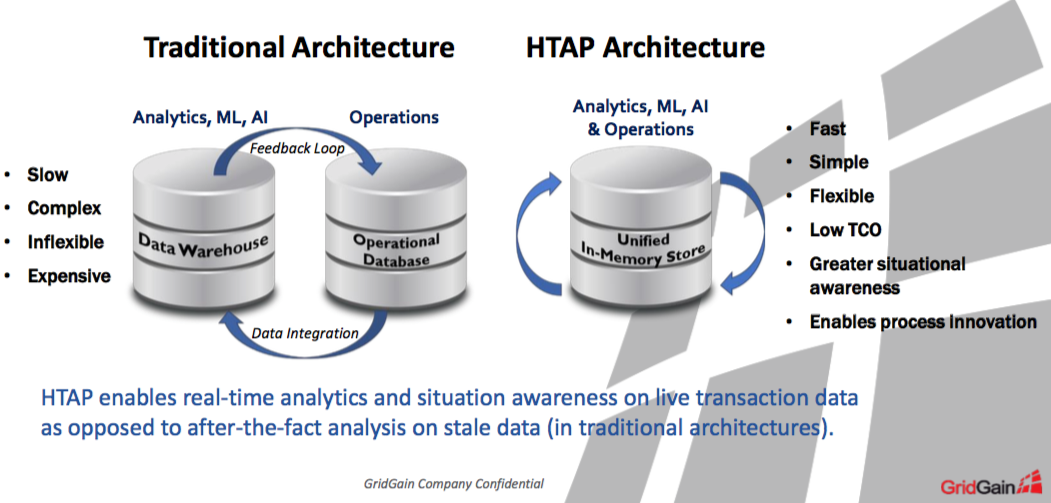
L'adoption d'une bases de données in-memory peut avoir un impact transformationnel sur l'entreprise.
L’éditeur se focalise sur deux marchés les services financiers et l’industrie. Parmi les clients de GridGain on peut toutefois citer la Société Générale, Barclays, ING dans le secteur bancaire mais également Apple (pour la partie distribution), Cognizant, Huawei (base en OEM dans le cloud OpenStack), Workday (avec Walmart près de 2 millions de clients) et même Microsoft (cloud security project). Mais le plus gros client reste la Sberbank avec un cluster fort de 2 000 nœuds (56 000 cœurs CPU, 1536 To de mémoire et une puissance de calcul de 2150 Tflops). Cette banque russe a construit l'un des plus grands clusters de bases de données in-memory au monde, comparable à AWS ou Alibaba. GridGain peut également compter sur le support de la communauté open source puisque le projet Ignite arrive dans le top 5 des solutions les plus téléchargées chez Apache - derrière Hadoop, Ambari, Lucene-Solr et Camel, avec 1 million de téléchargements par an.
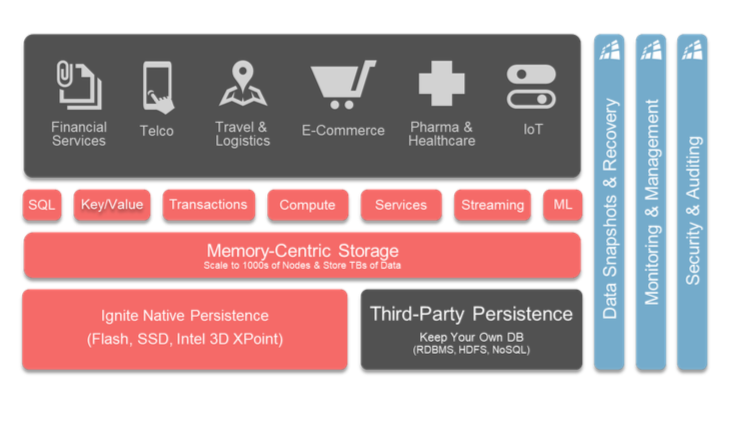
La base de donnée Ignite vient épauler les processus métiers dans de nombreux secteurs d'activité.
Apache Ignite 2.4 passe au machine learning
Signalons enfin que GridGain vient d’annoncer Professional Edition 2.4, reposant sur Apache Ignite 2.4. Cette mouture inclut un ensemble d’outils machine learning, qui inclut un réseau neuronal multicouche perceptron (MLP) permettant aux entreprises d'utiliser des algorithmes d'apprentissage machine avec leurs données opérationnelles (jusqu’au pétaoctet en temps réel). GridGain Professional Edition 2.4 améliore également les performances d'Apache Spark en introduisant une API pour Apache Spark DataFrames, qui s'ajoute à la prise en charge existante des RDD Spark.
Commentaire