Des chercheurs ont créé un moyen de stocker des données sous forme d'ADN, qui a l'avantage de se conserver pendant des dizaines de milliers d'années. La méthode de codage permettrait de stocker environ 100 millions d'heures de vidéo haute définition dans une tasse d'ADN, ont expliqué les scientifiques dans la revue Nature.
Ces experts anglais, travaillant à l'EMBL-EBI (European Bioinformatics Institute) à Cambridge, affirment avoir enregistré une version MP3 du discours de Martin Luther King « I have a dream », ainsi qu'une photo et plusieurs fichiers textes sur de l'ADN. « Nous savons déjà que l'ADN est une matière robuste pour stocker des informations, car nous en avons extrait des os de mammouth laineux, qui datent de dizaines de milliers d'années » précise un communiqué des scientifiques. Ils ajoutent « l'ADN est également incroyablement petit, dense et n'a pas besoin de puissance pour le stockage, le transport et la captation sont très faciles ».
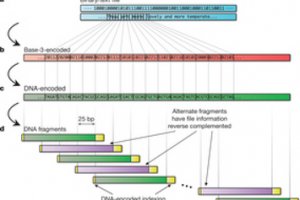
La lecture de l'ADN est relativement simple, par contre écrire dessus a été u obstacle majeur. Il existe deux problèmes : en utilisant les techniques actuelles, il est seulement possible de fabriquer de l'ADN avec des chaînes courtes. D'autre part, la lecture et l'écriture sont sujettes à des erreurs, en particulier lorsque la même lettre d'ADN est répétée.
Indexer les données sur plusieurs fragments d'ADN
Nick Goldman, directeur associé de l'EMBL-EBI, a décidé de créer un code qui surmonte ces deux problèmes. Cette méthode synthétise l'ADN à partir de l'information codée. Le laboratoire universitaire a travaillé avec la société californienne Agilent Technologies, un fabricant d'instruments de mesures électroniques et de bio-analytiques, pour transmettre les données, puis l'encoder dans l'ADN. La firme a téléchargé les fichiers sur le web, puis a ensuite synthétisé des centaines de milliers de fragments d'ADN pour indexer les données. L'objectif était d'éviter d'avoir une redondance des lettres d'ADN et donc des sources d'erreurs. « Le résultats ressemble à un petit morceau de poussière », explique Emily Leproust d'Agilent.
Le Dr Nick Goldman avec de l'ADN synthétisé
Cet échantillon a été envoyé à l'EMLB-EBI où les chercheurs ont réussi à séquencer l'ADN et décoder les fichiers sans erreurs. Nick Goldman constate, « nous avons créé un code qui est tolérant aux erreurs en utilisant une forme moléculaire. Nous savons que sa durée de vie sera bonne pendant 10 000 ans ». Il ajoute, « peut-être plus longtemps, tant que quelqu'un connaît le code et si on dispose d'une machine pour lire l'ADN ». La prochaine étape du développement est de perfectionner le système de codage et d'affiner les modalités pratiques ouvrant la commercialisation de cet ADN modifié.
Ce n'est pas la première fois que l'ADN est utilisé comme moyen de stockage. En août dernier, des scientifiques de l'Université de Harvard ont démontré la capacité de stocker un livre au format HTML dans l'ADN. Composé de 53 000 mots, de 11 images au format Jpeg et d'un programme JavaScript pour un poids total de 5,37 mégaoctets, le fichier a été stocké dans seulement un picogramme d'ADN, soit un milliardième de gramme.
En raison de la lenteur du processus de consignation des données, les scientifiques orientent l'ADN comme support pour l'archivage. « Le volume mondial des informations (1,8 zo) tiendrait dans environ 4 grammes d'ADN », souligne Sriram Kosuri, chercheur principal à l'Université de Harvard. En 2020, la production de données devrait atteindre 40 zettaoctets, soit l'équivalent de 5200 Go d'informations pour chaque habitant de la planète.
L'ADN, une solution pour le stockage de demain
L'infiniment petit pourrait venir au secours de la conservation des données informatiques. En effet, des chercheurs anglais ont affiné le procédé pour stocker des informations sur de l'ADN.