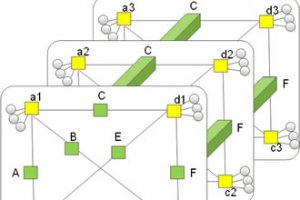
Pour son dernier super-computer, Fujitsu a décidé de regrouper des supercalculateurs en cluster afin de réduire le nombre de commutateurs réseau de 40 % sans perdre en performance. Le système repose à la fois sur un nouvel algorithme de communications qui permet de contrôler plus efficacement la circulation des données, mais aussi sur une topologie réseau multicouche à maillage intégral. À la différence de la topologie réseau « fat tree » à trois couches et de sa structure arborescente, la topologie à maillage intégral est plus efficace dans le sens où elle permet d'éliminer une couche de commutateurs.
Par ailleurs, la planification des transferts de données évite les collisions sur les trajets dans la mesure où chaque serveur communique avec tous les autres et réciproquement. Un système de superordinateurs en cluster composé de 6 000 serveurs aurait besoin de centaines ou de milliers de commutateurs réseau et il consommerait 20 % des besoins en électricité du système. Appliquée à un système de plusieurs milliers d'unités, l'approche de Fujitsu permettrait de réduire de 40% le nombre de commutateurs tout en maintenant le niveau de performance d'un système classique. « Par conséquent, il est possible de faire des économies sur toute la chaîne, aussi bien en nombre de composants utilisés, qu'en consommation d'énergie, ou en espace et en maintenance », a écrit un porte-parole de Fujitsu dans un courriel.
Selon Fujitsu, « cette technologie pourrait favoriser l'adoption de supercalculateurs dans des domaines comme l'analyse des tremblements de terre, la météorologie ou la recherche pharmaceutique ». Les supercalculateurs en cluster ont déjà été utilisés dans des secteurs qui vont de l'industrie du smartphone à celle de l'automobile. Fujitsu Laboratories devrait présenter sa technologie un peu plus tard ce mois-ci lors du Summer United Workshops on Parallel, Distributed and Cooperative Processing 2014 (SWoPP 2014) qui se tiendra dans la ville japonaise de Niigata City. Le Lab de Fujitsu prévoit de mettre cette en approche en pratique en proposant un modèle fonctionnel d'ici fin mars 2016. D'ici là, il va poursuivre ses recherches pour réduire encore plus le nombre de commutateurs réseau dans les supercalculateurs en cluster.