Alors que les agents d'IA se sont imposés dans tous les domaines, du service client à la résolution de problème de code, il est devenu de plus en plus important de déterminer quels sont les meilleurs pour une application donnée mais aussi les critères - pas uniquement fonctionnels - à prendre en compte. C'est là que l'analyse comparative entre en jeu. Depuis quelques mois, les benchmarks de LLM se sont d'ailleurs multipliés comme par exemple l'été dernier, avec la start-up Arthur qui a lancé Bench pour évaluer les modèles d'IA open source, plus récemment Salesforce pour évaluer les LLM orientés CRM, et aussi Anthropic finance des benchmarks pour mesurer efficacement les capacités avancées des modèles d'IA.
De récents travaux menés par des chercheurs de l'université de Princeton (AI Agents That Matter), s'intéressant spécifiquement aux agents d'IA (qui s'appuient de plus en plus sur des LLM) souligne ainsi que les processus actuels d'évaluation et d'étalonnage des agents présentent un certain nombre de lacunes entravant leur utilité dans les applications du monde réel. Les auteurs du rapport notent ainsi que ces lacunes encouragent le développement d'agents obtenant de bons résultats dans les tests de référence, mais pas dans la pratique, et proposent des moyens d'y remédier. "L'étoile polaire de ce domaine est de construire des assistants comme Siri ou Alexa et de les faire fonctionner réellement, en gérant des tâches complexes, en interprétant avec précision les demandes des utilisateurs et en réalisant des performances fiables", indique un billet de blog signé par deux des chercheurs de l'étude, Sayash Kapoor et Arvind Narayanan. "Mais c'est loin d'être une réalité, et l'orientation même de la recherche est relativement nouvelle." Selon l'article, il est ainsi difficile de distinguer les avancées réelles du battage médiatique. En outre, les agents sont suffisamment différents des modèles linguistiques pour que les pratiques d'évaluation comparative soient repensées.
Le comportement d'un agent IA de plus en plus complexe
Un agent IA perçoit et agit sur son environnement, mais à l'ère des grands modèles de langage (LLM), son comportement devient de plus en plus complexe. Selon les chercheurs, trois catégories de propriétés caractérisent un système d'IA orienté agents. Tout d'abord leurs environnements et objectifs (dans une situation plus complexe davantage de systèmes d'IA sont orientés agents et beaucoup d'entre eux poursuivent des objectifs complexes sans instruction). Ensuite en termes d'interface utilisateur et de supervision (les systèmes d'IA agissant de manière autonome ou acceptant des entrées en langage naturel sont davantage orientés agents, notamment ceux qui en nécessite moins de la part de l'utilisateur). Enfin en matière de conception, certains systèmes recourant à des outils tels que la recherche sur le web, la planification (comme la décomposition des objectifs en sous-objectifs) ou dont le contrôle du flux est piloté par un LLM, sont aussi davantage orientés agents.
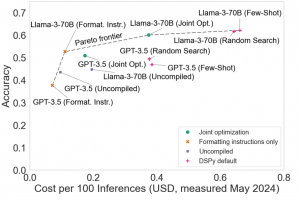
L'étude a abouti à cinq conclusions principales, toutes étayées par des études de cas. A savoir d'abord que les comparatifs d'agents d'IA doivent faire l'objet d'un contrôle des coûts : étant donné que les appels répétés aux modèles sous-jacents (dont le coût augmente à chaque fois) peuvent augmenter la précision, les chercheurs sont tentés de concevoir des agents extrêmement coûteux pour arriver en tête. Mais l'article décrit trois agents de base simples mis au point par les auteurs, surpassant de nombreuses architectures complexes à un coût bien moindre... Ensuite l'optimisation conjointe de la précision et du coût peut permettre une meilleure conception des agents : deux facteurs déterminent le coût total de fonctionnement d'un agent, à savoir les coûts uniques liés à l'optimisation de l'agent pour une tâche, et les coûts variables encourus à chaque fois qu'il est exécuté. Or les auteurs montrent qu'en consacrant plus d'argent à l'optimisation initiale, il est possible de réduire les coûts variables tout en maintenant la précision.
Sortir du dilemme coût versus précision
L'analyste Bill Wong, chargé de recherche en IA à Info-Tech Research Group, est de cet avis : "L'accent mis sur la précision est une caractéristique naturelle sur laquelle il convient d'attirer l'attention lors de la comparaison des LLM", a-t-il déclaré. "Il est raisonnable de suggérer que l'inclusion de l'optimisation des coûts donne une image plus complète de la performance d'un modèle, tout comme les repères de base de données basés sur TPC ont tenté de fournir une mesure de performance pondérée avec les ressources ou les coûts impliqués pour fournir une mesure de performance donnée." Les chercheurs et développeurs de modèles ont des besoins différents en matière d'évaluation comparative et ne tiennent généralement pas compte du coût lors de leurs évaluations, alors que pour les autres développeurs en aval, le coût est un facteur clé. "L'évaluation des coûts se heurte à plusieurs obstacles", note le document. "Différents fournisseurs peuvent facturer des montants différents pour le même modèle, le coût d'un appel à l'API peut changer du jour au lendemain et varier en fonction des décisions du développeur du modèle, par exemple si les appels API en masse sont facturés différemment. Les auteurs suggèrent de rendre les résultats des benchmarks personnalisables en utilisant des mécanismes pour ajuster le coût d'exécution des modèles. Par exemple en proposant aux utilisateurs de déterminer le coût des jetons d'entrée et de sortie pour le fournisseur de leur choix et les aider à réévaluer le compromis coût versus précision. Pour les évaluations d'agents IA en aval, rester attentif au nombre de jetons d'entrée et de sortie et recalculer les coûts au fil de l'eau pour décider si l'agent IA reste toujours un bon choix est également à considérer.
Les critères d'évaluation des agents permettent sans doute de gagner du temps mais ils ne sont utiles que s'ils reflètent la précision du monde réel, note le rapport. En cas d'ajustement excessif d'un modèle étroitement adapté à ses données d'apprentissage qu'il ne peut pas faire de prédictions ou de conclusions précises à partir de données autres que les données d'apprentissage, aboutissent à des repères dont la précision n'est pas transposable dans le monde réel. "Il s'agit d'un problème beaucoup plus grave que la contamination des données d'entraînement du LLM, car la connaissance des échantillons de test peut être directement programmée dans l'agent au lieu d'être simplement exposée à ces échantillons pendant l'entraînement", indique le rapport. Les évaluations des agents manquent de normalisation et de reproductibilité, et en l'absence d'évaluations reproductibles des agents, il est difficile de savoir s'il y a eu de véritables améliorations. Ce qui ne va pas sans induire en erreur les développeurs en aval lors de la sélection des agents pour leurs applications.
Réduire la dépendance aux LLM monolithiques
Toutefois, comme Sayash Kapoor et Arvind Narayanan l'ont noté dans leur blog, ils sont prudemment optimistes quant à l'amélioration de la reproductibilité de la recherche sur les agents d'intelligence artificielle, car les codes et les données utilisés pour élaborer les articles publiés sont de plus en plus partagés. "Une autre raison est que les recherches trop optimistes sont rapidement confrontées à la réalité lorsque des produits basés sur des évaluations trompeuses finissent par échouer", ont ajouté les chercheurs.
Malgré l'absence de normes, Bill Wong d'Info-Tech a déclaré que les entreprises cherchaient toujours à utiliser des agents dans leurs applications. "Je reconnais qu'il n'existe pas de normes pour mesurer les performances des applications d'IA basées sur des agents", a-t-il fait remarquer. "Malgré cela, les entreprises affirment qu'il y a des avantages à poursuivre des architectures basées sur des agents pour obtenir une plus grande précision et réduire les coûts et la dépendance à l'égard des LLM monolithiques. L'absence de normes et l'accent mis sur les évaluations basées sur les coûts vont probablement se poursuivre, a-t-il déclaré, car de nombreuses sociétés considèrent la valeur que les solutions de GenAI peuvent apporter. Cependant, le coût n'est qu'un des nombreux facteurs à prendre en compte. Les entreprises avec lesquelles il a travaillé considèrent que les facteurs tels que les compétences requises, la facilité de mise en œuvre et de maintenance, ou encore l'évolutivité comptent plus que le coût lors de l'évaluation des solutions. Et d'ajouter: "Nous commençons à voir de plus en plus d'entreprises dans divers secteurs où la durabilité est devenue un facteur essentiel pour les cas d'usage de l'IA qu'elles poursuivent. La technologie d'agents IA est donc la voie de l'avenir, car elle utilise des modèles plus petits, ce qui réduit la consommation d'énergie tout en préservant, voire en améliorant, les performances des modèles."