De nombreux outils, basés sur l’IA, permettent de générer du code. GitHub est le dernier exemple en date, avec son assistant Copilot élaboré avec OpenAI (le laboratoire d'intelligence artificielle fondé par Elon Musk). Des systèmes comme celui-ci permettent de réduire drastiquement le temps que les développeurs passent à coder, leur permettant ainsi d’être plus productifs, en réduisant les tâches répétitives et en les aidant à se concentrer sur d’autres tâches plus complexes. Cependant, certaines erreurs persistent et les systèmes existants possèdent leurs propres limites. Dans ce sens, Salesforce a mis en libre accès un système d’apprentissage automatique appelé CodeT5 qui peut comprendre et générer du code en temps réel. Des performances ont déjà été notées notamment concernant les tâches de codage, la détection de défauts dans le code et la vulnérabilité aux exploits.
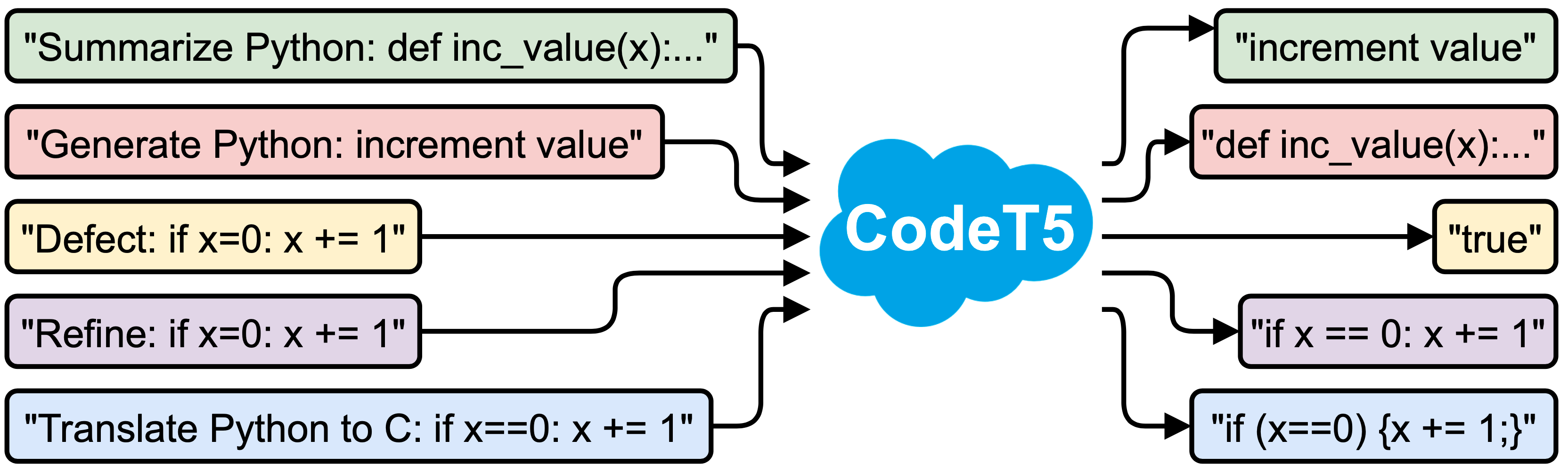
Le CodeT5 permet une large gamme d'applications d'intelligence de code notamment pour les tâches de compréhension et de génération liées au code. (Crédit : Salesforce)
CodeT5 s'appuie sur le cadre T5 (Text-to-Text Transfer Transformer) de Google, qui a été détaillé pour la première fois dans un article publié en 2020. Il recadre les tâches de traitement du langage naturel dans un format unifié de texte à texte, où les données d'entrée et de sortie sont toujours des chaînes de texte - ce qui permet d'appliquer le même modèle à pratiquement toutes les tâches de traitement du langage naturel. Pour entraîner CodeT5, l'équipe a trouvé plus de 8,35 millions d'instances de code, y compris des commentaires écrits par les utilisateurs, dans des dépôts GitHub ouverts et accessibles au public.
Des résultats prometteurs
Dans un billet de blog, des membres de Salesforce, Yue Wang et Steven Hoi (directeur général de la recherche pour Salesforce Asie), ont expliqué que CodeT5 s'appuie sur l'architecture similaire de T5 mais intègre des connaissances spécifiques. Il prend le code et les commentaires qui l'accompagnent comme une entrée de séquence. Les premiers résultats ont montré que CodeT5 atteint des bonnes performances sur 14 sous-tâches dans un benchmark de code CodeXGLUE.
Salesforce présente ses résultats sur la synthèse du code (à gauche) et la génération de texte en code (à droite). (Crédit : Salesforce)
Il surpasse considérablement le modèle SOTA précédent PLBART sur toutes les tâches de génération, y compris la synthèse de code, la génération de texte en code, la traduction de code en code et le raffinement de code. Concernant la compréhension des tâches, il donne une meilleure précision sur la détection des défauts et des résultats comparables sur la détection des clones. En outre, nous observons que la double génération bimodale stimule principalement les tâches NL-PL telles que la synthèse de code et la génération de texte à code.
Les risques de l’automatisation
Bien sûr, certains risques éthiques persistent comme l’indique Salesforce dans son billet. « Les ensembles de données d'entraînement de notre étude, y compris les commentaires écrits par les utilisateurs, sont du code provenant de référentiels Github open source et accessibles au public. Cependant, il est possible que ces ensembles de données encodent certains stéréotypes tels que la race et le sexe à partir des commentaires textuels ou du code source tels que des variables, des fonctions et des noms de classe. En tant que tels, les préjugés sociaux seraient intrinsèquement intégrés dans les modèles formés sur eux.
Le déploiement de CodeT5 implique par ailleurs un biais d'automatisation des systèmes de machine learning. « Parfois, ces systèmes peuvent produire des fonctions qui semblent superficiellement correctes mais ne correspondent pas réellement aux intentions du développeur. Si les développeurs adoptent involontairement ces suggestions de code incorrectes, cela pourrait leur allonger le temps de débogage et même entraîner des problèmes de sécurité importants » indique les chercheurs de Salesforce. Le facteur sécurité n’est pas à prendre à la légère : les modèles pré-entraînés peuvent coder certaines informations sensibles (par exemple, des adresses personnelles) à partir des données d'entraînement. « Bien que nous ayons effectué plusieurs cycles de nettoyage des données pour atténuer ce problème avant de former nos modèles, il est toujours possible que certaines informations sensibles ne puissent pas être complètement supprimées ». La production de code vulnérable pourrait nuire au logiciel et même bénéficier au développement avancé de logiciels malveillants lorsqu'il est délibérément mal utilisé, un risque non négligeable face à l’augmentation des cyberattaques dans le monde.