")
Tableau Software attend 14 000 participants sur la 10ème édition de sa conférence utilisateurs TC17, qui se tient à Las Vegas jusqu'au 12 octobre. C’est l’occasion pour l’éditeur d'outils d’analyse et de visualisation de données de faire un point sur les développements entrepris par ses équipes de R&D. François Ajenstat, responsable de la gestion des produits, a ainsi annoncé la bêta de Tableau 10.5 ainsi que la bêta d'Hyper, moteur de base de données en mémoire. La plateforme analytique arrive également dans sa version Linux.

Dans la version 10.5 de la plateforme analytique, il sera possible d'afficher des détails d'une visualisation de données en passant la souris sur un point.
Une démonstration d'Hyper a été présentée sur la conférence. L’assistance a pu constater ses capacités à manipuler 500 millions de lignes de données en moins d’une seconde. Le moteur in-memory (issu d’un projet de recherche de l’Université technique de Munich) améliore aussi les performances sur l’extraction et les requêtes. Il permettra ainsi aux entreprises de disposer des données les plus récentes, même sur des jeux volumineux et complexes, ainsi que l’éditeur le résume dans un billet. Hyper tire aussi parti des infrastructures matérielles actuelles pour améliorer les débits sur les transactions.
Project Maestro : data wrangling au menu

Sur TC17, Anushka Anand, Senior Product Manager de Project Maestro. (crédit : Tableau)
A l’attention des développeurs, Tableau a par ailleurs annoncé une préversion des API Extensions, accessible sur inscription. Celles-ci permettront de créer des extensions aux dashboards pour que les utilisateurs puissent interagir avec des applications externes sans quitter Tableau. Enfin, l’éditeur a également donné des nouvelles de son projet de data wrangling baptisé Maestro. Celui-ci proposera une approche très visuelle sur les étapes de préparation, de nettoyage et de transformation des données destinées à l’analyse.
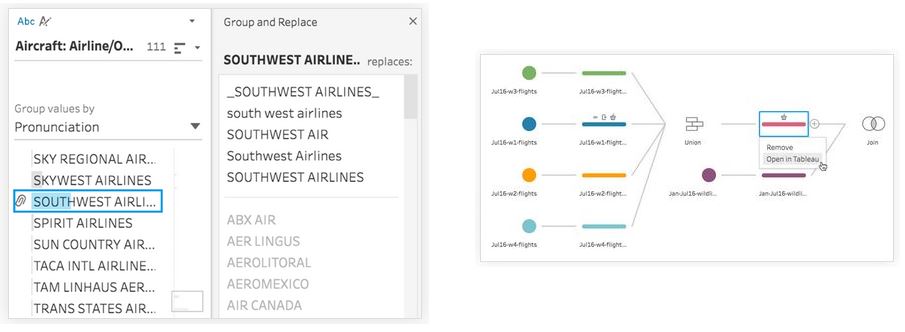
« Maestro montre automatiquement les erreurs et les cas particuliers sur les données », explique l’éditeur. « Et il recourt au regroupement flou [fuzzy clustering] pour alléger les tâches courantes et répétitives telles que la correction des fautes d’orthographe ou la réconciliation des entités à travers les sources de données ». Project Maestro sera accessible en version bêta au cours de ce trimestre.
Commentaire