 renforce le contraste des tableaux de bord pour les environnements SOC et NOC. (Crédit : Splunk)")
La plateforme d’analyses des données machine de Splunk couvre une large palette de cas d’usage, ainsi que l’illustre la diversité des témoignages proposés par ses clients (Engie Global Markets, Vodafone, Generali, Feu Vert, etc.). Mais l’éditeur américain veut maintenant étendre sa base d’utilisateurs au-delà de la DSI et des équipes de cybersécurité. Avec son approche de développement produit Splunk Next, il veut apporter ses outils vers davantage d’utilisateurs. Au départ, la plateforme d’analyse big data permettait aux responsables informatiques d’indexer et de faire parler leurs données machines (logs, configuration, files de messages, événements…). Elle a évolué ensuite vers la sécurité pour lutter contre les cybermenaces. « Une grande partie de notre succès est venue des équipes IT et de sécurité, ce qui représente toujours le cœur de notre ADN, mais il y a des catégories d’utilisateurs dans l’entreprise qui ne savent encore rien de Splunk », a exposé Jon Rooney, responsable marketing produits en amont de la conférence Splunk 18 à Orlando (du 1er au 4 octobre).
Dans cette perspective, l’éditeur a présenté à Orlando une série de programmes en mode bêta. Il fait ainsi évolué son app mobile sous iOS pour lui ajouter des fonctionnalités de recherche en langage naturel. L’app inclut des alertes et une authentification simplifiée, ainsi que la possibilité de déclencher directement des actions. Jon Rooney donne un exemple d’utilisation. « Vous vous trouvez à un événement sportif et vous recevez une alerte de Splunk ». Pas besoin d’ordinateur portable ni de VPN pour intervenir. « Vous pouvez interagir avec des tableaux de bord, par exemple pour fermer un port sur le téléphone ». Quant à la recherche en langage naturel, elle permet de s’abstraire de la complexité du langage de recherche de Splunk et des approches réservées aux power users, indique le directeur marketing produits. « Nous voulons créer une couche d’expérience pour que d’autres utilisateurs puissent tirer profit de Splunk ». Cela inclut la possibilité d’interagir avec les données de la plateforme via un assistant vocal ou un chatbot à travers la messagerie instantanée Slack.
Business Flow visualise les flux des processus métiers
Cette ouverture fait évoluer Splunk sur le marché des applications analytiques, un terrain où il va se trouver en concurrence avec des acteurs comme Tableau ou Qlik. Mais Splunk veut s’appuyer sur ses forces et son objectif n’est pas de proposer une expérience de tableaux de bord très bien présentés au-dessus de données très structurées. « Notre particularité, c’est notre capacité à corréler et à donner du sens à des données qu’on ne pourra jamais mettre dans une base de données relationnelle avec une couche de BI au-dessus, l’objectif c’est toujours d’extraire de l’information à partir du chaos », pointe Jon Rooney. « Les utilisateurs qui veulent accéder au bare metal le feront toujours et nous allons continuer à nous adresser à l’utilisateur avancé avec de nombreuses améliorations autour de Splunk Enterprise ».
Un exemple d’incursion de Splunk dans les métiers est illustré par Business Flow. Actuellement en bêta, celui-ci s’adresse à l’univers BI traditionnel. Il permet de visualiser un ensemble de flux liés à des processus métiers ou à des parcours clients en ligne pour déceler des tendances et prendre des décisions. Jon Rooney donne l’exemple d’un responsable de produit en ligne qui souhaite voir de quelle façon un client progresse à travers le produit, et qui peut faire remonter les informations « sur un mode davantage drag and drop et plus visuel ». La récente implication de Splunk dans l’Internet des objets est une autre illustration de son intention d’atteindre de nouvelles catégories d’utilisateurs, avec un produit destiné au secteur industriel. Celui-ci permet d’effectuer de la maintenance prédictive pour des clients tels que BMW. « Nous avons fait de nombreuses études de marché et parlé à des clients pour savoir quelle serait la bonne tête de pont pour nous dans l’IoT et par quoi nous pourrions commencer », explique M.Rooney. « A l’évidence, il y a de multiples opportunités, mais nous n’avons pas voulu tout intervenir dans tous les domaines ».
Des recherches à très grande échelle avec Data Fabric Search
Splunk Next doit permettre d’inclure davantage de sources de données et d’utilisateurs. Des mises à jour sont prévues sur l’ensemble du portefeuille de solutions dont Phantom et VictorOps, mais le périmètre va s’étendre au-delà. Parmi les annonces d’Orlando, on trouve ainsi Data Stream Processor et Data Fabric Search. Le premier logiciel permet aux clients d’aller plus loin avec leurs données en mouvement avant qu’elles soient indexées. Le deuxième est une fonctionnalité de recherche qui peut fonctionner à l’échelle à travers les index. Avec Data Fabric Search, il sera possible d'effectuer des recherches sur des milliards d'événements en quelques millisecondes à travers une recherche fédérée sur plusieurs déploiements Splunk, assure l'éditeur.
Jon Rooney met les nombreuses annonces faites à Orlando en parallèle avec les récentes acquisitions réalisées (Phantom, VictorOps, SignalSense et Rocana) qui ont aidé à faire croître les équipes produits de l’éditeur de 55% l’an dernier. A travers ses acquisitions, Splunk a cherché des compétences nées dans le cloud et le big data qui apportent de la vélocité sur les produits. VictorOps est un outil de collaboration pour aider les équipes devops à accélérer la résolution des problèmes. Phantom apporte des capacités d’automatisation et d’orchestration aux équipes de sécurité. La prochaine étape pour Splunk consiste à utiliser ces acquisitions pour élargir sa base d’utilisateurs. Phantom est un acteur de la sécurité, mais son acquéreur devrait s’appuyer sur ses capacités sous-jacentes pour appliquer son offre à de multiples cas d’usages en commençant par l’IT. A l’inverse pour VictorOps, qui se présente comme une plateforme de collaboration et gestion d’incidents IT et dont les capacités peuvent être étendues aux clients dans la sécurité.
Splunk Enterprise 7.2 déployable en containers
Parmi les nouveautés de Splunk Cloud et Splunk Enterprise annoncées par l'éditeur à Orlando, le SmartStore permet une meilleure gestion du stockage des données, tandis que Workload Management hiérarchise l'attribution des ressources de calcul et de mémoire utilisées pour les recherches et les alertes. Le déploiement en mode containers est possible avec la version 7.2 d'Enterprise à travers Splunk for Docker. La solution permet aussi d'archiver certaines données plus rarement exploitées pour se conformer aux exigences réglementaires.
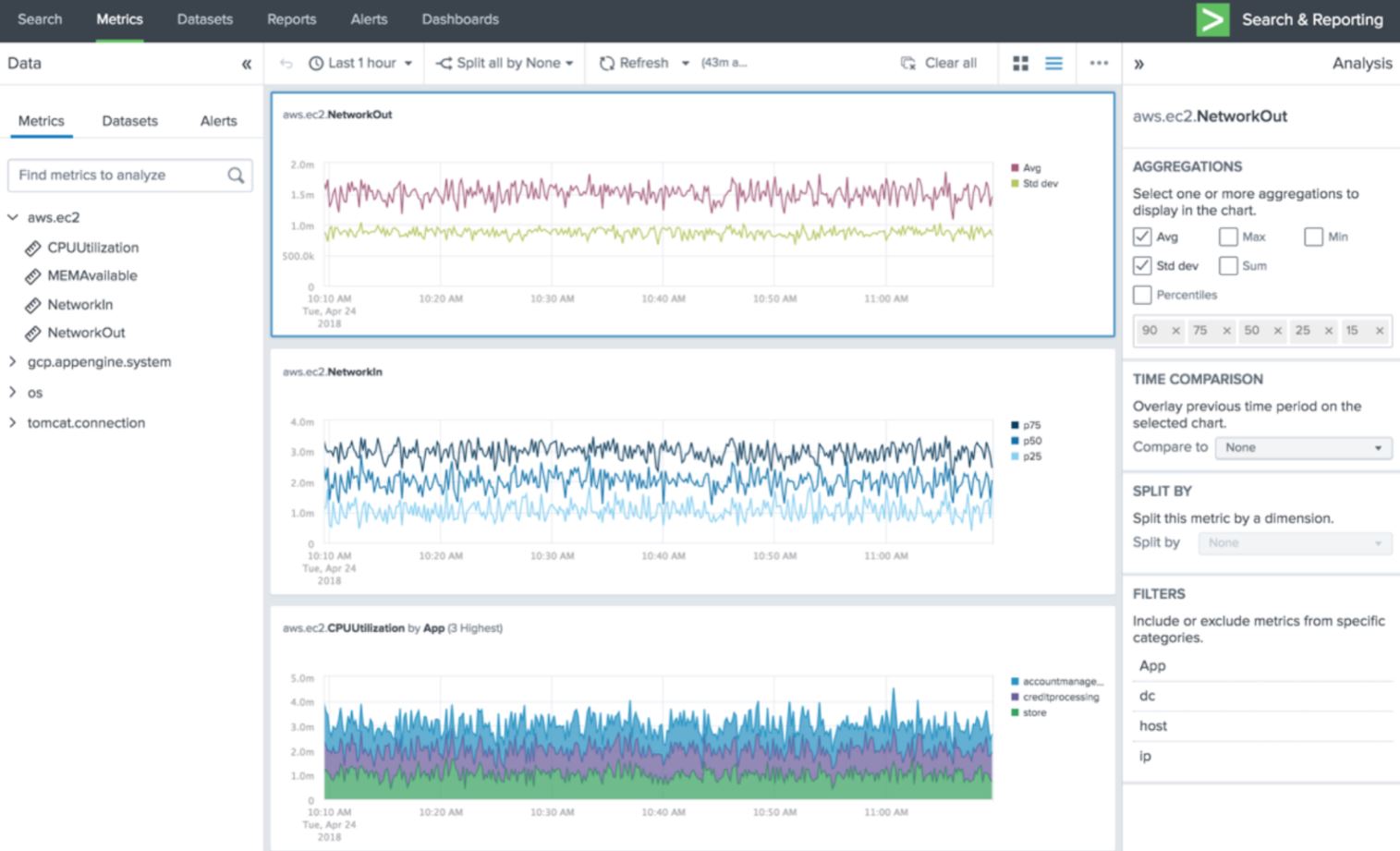
Avec Metrics Workspace, Splunk dit proposer une interface intuitive pour permettre à ses utilisateurs de surveiller leurs indicateurs.
De nouvelles fonctionnalités concernent aussi l'exploration des données, avec Metrics Workspace, une interface d'analyse des métriques et un mode de visualisation sombre (dark mode) qui fournit un contraste visuel plus lisible dans les environnements SOC et NOC. Le reporting Health Report permet par ailleurs aux administrateurs de Splunk de comprendre rapidement l'état de leur environnement.
Enrichir ses algorithmes de ML avec la communauté Splunk
Splunk continue aussi à investir dans l’apprentissage machine pour récupérer plus vite les informations, par exemple en faisant évoluer les fonctions d’analyse du comportement qui permettent la détection de menaces internes ou, pour les équipes de sécurité, la détection d’anomalies. « C’est important, avec la pénurie de compétences qui perdure, les entreprises ne peuvent pas recruter suffisamment, de pouvoir s’appuyer sur la technologie pour prendre en charge la première ligne de défense », estime le directeur marketing.
De plus en plus, Splunk fournit aussi davantage d’alertes prédictives aux utilisateurs de son produit IT Service Intelligence en version 4.0. Par ailleurs, les utilisateurs du MLTK, le Machine learning Toolkit peuvent partager leurs algorithmes sur Github et s’appuyer sur les contributions de la communauté. Tandis que MLTK Container for Tensorflow leur permet d’étendre les capacités du toolkit avec les fonctionnalités apportées par Tensorflow. Enfin, le nouveau connecteur MLTK pour Apache Spark permet de puiser dans la vaste bibliothèque d’apprentissage machine MLib.
Commentaire