")
Sur l’évènement Re :Invent qui se déroule à Las Vegas (du 2 au 6 décembre), AWS était attendu sur l’IA. Le fournisseur de cloud a répondu à l’appel en présentant des fonctionnalités et des outils pour les développeurs dont voici les différentes annonces.
SageMaker Unified Studio
Actuellement disponible en preview, le service SageMaker Unified Studio combine l'analyse SQL, le traitement des données, le développement des applications IA, le streaming de données, la business intelligence et la recherche analytique. « SageMaker Unified Studio rassemble des fonctions de plusieurs studios autonomes que les spécialistes de l’analytique et datascientist utilisent aujourd'hui dans AWS, notamment des éditeurs de requêtes autonomes et divers outils visuels », a expliqué Matt Garman, CEO d’AWS. Il a aussi présenté SageMaker Lakehouse, une base de données compatible avec les tables Apache Iceberg. L'offre est disponible dès maintenant pour tous.
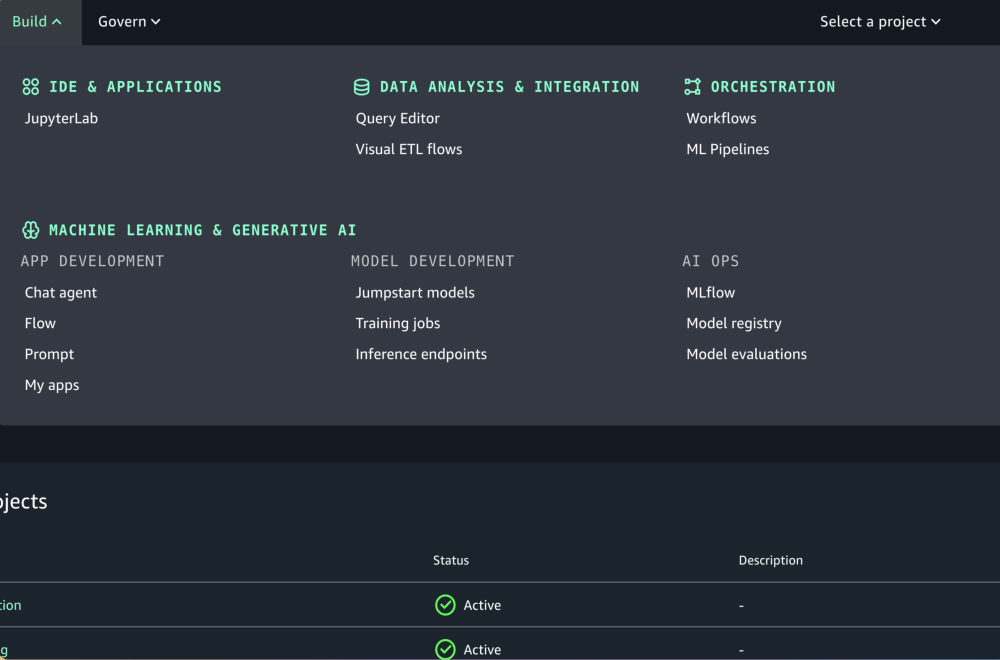
Sagemaker Unified Studio centralise plusieurs tâches pour les développeurs. (Crédit Photo : AWS)
Mises à jour pour Q Developer
En 2023, Adam Selipsky, alors CEO d'AWS, avait présenté pour la première fois Amazon Q, réponse de l'entreprise à Copilot, l'assistant d'IA générative piloté par GPT de Microsoft. Cette année, Matt Garman a présenté des mises à jour pour les capacités d’automatisation des tâches de codage, en particulier des fonctions d'automatisation des révisions de code, des tests unitaires et la génération de documentation pour Q Developer. Selon le dirigeant, ces ajouts allégeront la charge de travail des développeurs et les aideront à achever leurs tâches de développement plus rapidement.
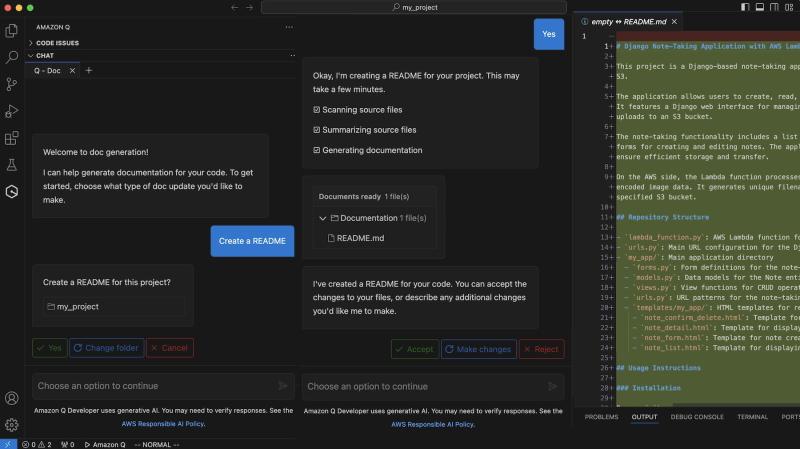
Q Developer s'étoffe de nouvelles fonctions. (Crédit Photo : AWS)
Par ailleurs, AWS a dévoilé en avant-première plusieurs capacités de traduction de code pour Q, notamment la possibilité de moderniser les applications .Net de Windows vers Linux, la modernisation du code mainframe et une aide à la migration des instances VMware. Matt Garman a indiqué que Q Developer pouvait être utilisé pour enquêter sur des problèmes opérationnels et les résoudre. Cette fonctionnalité, actuellement en avant-première, pourra orienter l'utilisateur dans ses diagnostics opérationnels et automatiser l'analyse des causes profondes des problèmes dans les charges de travail.
Distillation de modèles et implémentation d'agents pour Bedrock
Lors de sa présentation, Matt Garman a aussi mis l'accent sur Bedrock, la plateforme propriétaire d'AWS pour la création de modèles et d'applications d'IA générative. En particulier, il a annoncé le service managé Model Distillation, toute première mise à jour de Bedrock, disponible en preview. Cette solution doit aider les entreprises à réduire leurs coûts d'exploitation des LLM. Le processus de distillation de modèles consiste à utiliser les connaissances spécialisées d'un LLM de grande taille pour créer un LLM plus petit pour un cas d’usage spécifique. Les entreprises choisissent souvent cette technique pour réduire les coûts et une exécution plus rapide. Comme l’a expliqué le CEO, « Model Distillation est proposé en tant que service géré, car le processus de distillation d'un modèle plus grand peut s’avérer assez lourd : les experts en ML doivent s’occuper des données d'entraînement et les workflow, régler les paramètres du modèle et surveiller le poids du modèle ». Le service fonctionne en générant des réponses à partir de modèles dits ‘enseignant’ et en affinant un modèle dit ‘étudiant’. Il utilise également des techniques de synthèse de données pour améliorer la réponse d'un modèle ‘enseignant’.
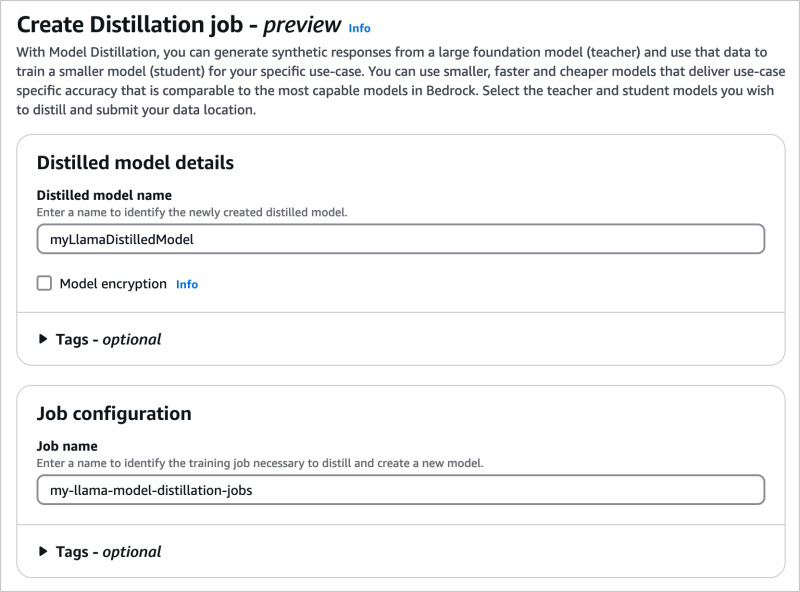
Il est possible dans Bedrock de distiller des LLM pour en faire des plus petits et plus spécialisés. (Crédit Photo: AWS)
Par ailleurs, le CEO a dévoilé la fonction Automated Reasoning Checks, actuellement en avant-première. Ajoutée aux Guardrails, elle prévient les erreurs factuelles dues aux hallucinations, en utilisant des processus de vérification et de raisonnement algorithmiques mathématiques et logiques pour vérifier les informations générées par un modèle. Suivant les traces de ses rivaux, AWS a désormais ajouté la prise en charge de la collaboration multi-agents dans Bedrock Agents en avant-première. Parmi les mises à jour de Bedrock, on peut encore citer des fonctionnalités destinées à aider les entreprises à rationaliser les tests d'applications avant leur déploiement.
Des modèles multimodaux et des instances sur Trainium 2
Depuis un certain temps, et surtout depuis le mois de juin de cette année, plusieurs rumeurs laissaient entendre qu'AWS se préparait à commercialiser un LLM concurrent de ceux d'OpenAI, de xAI et de Google. Mardi, Matt Garman a dévoilé une série de LLM appelée Nova, qui, selon lui, sera au moins équivalente, si ce n’est meilleure, que les modèles concurrents, notamment en termes de coût. La famille Nova comprend Micro, un modèle de génération de texte à texte, Lite, Pro et Premier. Tous les modèles sont généralement disponibles, à l'exception de Premier, qui devrait être disponible d'ici le mois de mars. Le fournisseur a indiqué qu’il prévoyait également de lancer deux autres modèles au cours de l'année à venir sous les noms de Nova Speech to Speech et Nova Any to Any.
Outre cette série de mises à jour logicielles pour les développeurs, AWS a aussi commercialisé sa puce Trainium2 pour améliorer le support des charges de travail d'IA générative. Les instances EC2 alimentées par AWS Trainium2 sont désormais disponibles. Cette puce d'accélération pour les charges de travail d'IA et d'IA générative a été présentée pour la première fois l'année dernière. Selon le fournisseur, les instances EC2 alimentées par Trainium2 sont quatre fois plus rapides, disposent de quatre fois plus de bande passante mémoire et ont trois fois plus de capacité mémoire que la génération précédente alimentée par les puces Trainium1.
Commentaire