")
A l’occasion de sa conférence Snowday 2021, le fournisseur de datawarehouses cloud Snowflake a présenté les ajouts récents faits aux fonctionnalités de son Data Cloud, plateforme d’unification de données dans l’entreprise permettant aussi de les partager avec d’autres organisations au niveau mondial. Data Cloud fournit une expérience unifiée à travers les différents clouds et régions où se trouvent les données en s’appuyant sur ses capacités de réplication cross-cloud et de récupération en temps réel (failover) sur ses bases de données. Comme annoncé en juin, l’éditeur créé en 2012 en Californie par deux Français commence maintenant à supporter Python dans son framework de développement Snowpark. Il proposait déjà Snowpark pour Java et pour Scala. Comme eux, la déclinaison pour Python est intégrée nativement dans le moteur de Snowflake. L’un des intérêts du langage est de disposer d’un vaste écosystème de packages open source pour la data science et il est fréquemment utilisé par les équipes travaillant sur les données pour bâtir les pipelines de traitement, les workflows d’apprentissage machine et développer des applications. Pour l’instant, Snowpark pour Python n’est accessible qu’en préversion privée. Avec ce support, les utilisateurs du langage vont pouvoir l’utiliser sans avoir à copier ou déplacer des données, l’ensemble du code s’exécutant dans une sandbox sécurisée directement dans Snowflake, explique le fournisseur. Les développeurs souhaitant s’inscrire pour en obtenir la préversion publique peuvent s’inscrire en ligne.
Le framework de développement de Snowflake bénéficie de plusieurs autres évolutions. Les API Snowpark et les fonctions Java définies par l’utilisateur (UDF), déjà disponible sur AWS depuis juin, le sont maintenant sur le cloud public Azure de Microsoft et sur celui de Google (en préversion privée). Sur les fonctions Java, le support des fonctions table est livrée en préversion publique à travers tous les clouds supportés. C’est une avancée importante par rapport aux fonctions scalar. Toujours sur Java dans Snowpark arrive aussi le support des procédures stockées (en préversion privée) et celui des données non structurées qui peuvent être traitées dans Snowflake avec Snowpark. On peut notamment lire les données EXIF des images en même temps que les données structurées et semi-structurées gérées dans le datawarehouse cloud.
Réplication des comptes inter-clouds et inter-régions
Du côté de la plateforme Data Cloud, un certain nombre d’évolutions ont également été annoncées sur Snowday 2021. Snowflake met en avant celles qu’il a réalisées sur la réplication des données, avec une amélioration de performance allant jusqu’à 55% chez un de ses clients, ce qui a permis à ce dernier de réduire d’autant ses coûts de réplication puisque le paiement se fait à l’utilisation, rappelle l’éditeur dans un billet de blog. Pour les entreprises opérant au niveau mondial, Snowflake propose maintenant la réplication des comptes inter-clouds et inter-régions, ce qui permet de synchroniser automatiquement entre les clouds et les régions l’ensemble des métadonnées d’un compte, dont les contrôles d’accès par rôle et identités, les politiques de gouvernance et les éléments de surveillance des ressources, de façon cohérente par rapport à la région d’origine. Ces fonctions viennent compléter les capacités Client Redirect annoncées en septembre, et désormais en préversion publique, pour rediriger les connexions clientes de façon transparente entre les comptes Snowflake situés sur différents clouds et régions et assurer la continuité d’activité.
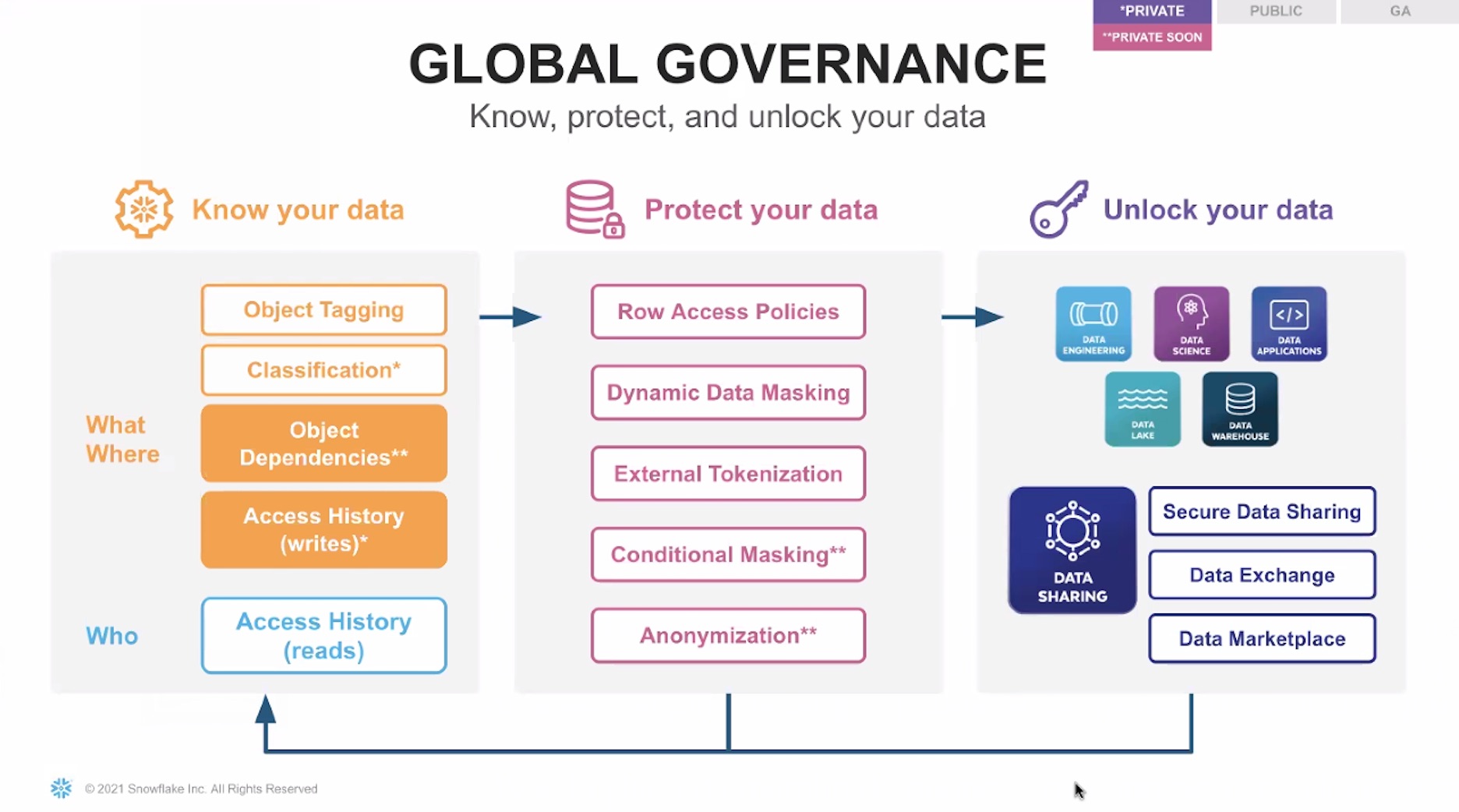 Pour une bonne gouvernance, des informations sur le lignage des données sont fournies dans Access History. (Crédit : Snowflake)
Pour une bonne gouvernance, des informations sur le lignage des données sont fournies dans Access History. (Crédit : Snowflake)
Sur la gouvernance et la protection des données, Snowflake introduit une visibilité sur le lignage des données dans Access History, pour l’instant en préversion privée. Cette capacité s’applique aussi aux données venant de sources externes récupérées dans Snowflake, afin de pouvoir vérifier les sources sensibles et satisfaire aux exigences réglementaires. Le fournisseur a par ailleurs mis sur pied un programme baptisé Accelerated Governance pour faciliter à ses clients l’accès aux solutions et intégrations proposées par ses partenaires dans ce domaine.
Enfin, comme déjà évoqué avec Snowpark, pour réduire les silos entre données structurées et non structurées, Snowflake avance sur la prise en compte de ces dernières. Le fournisseur les supporte sur sa plateforme dans une préversion publique qui fournit une expérience unifiée à travers différents types de données. Cela s’étend aux capacités de partage, avec des vues sécurisées qui référencent les données non structurées, ou encore à leur enrichissement via la Data Marketplace.
Commentaire