")
OpenAI met les bouchées doubles. Depuis le lancement de son chatbot fin 2022, la start-up est au centre de toutes les attentions et elle compte bien s’en servir. Même si elle est enregistrée en tant que société à but lucratif plafonné, elle a su monétiser ses services basés sur des différents modèles d'IA, à commencer par ChatGPT avec le lancement d'une offre premium, ChatGPT Plus, en février. Aujourd’hui, elle fait un pas de plus dans cette valorisation en introduisant des API à destination des entreprises ; ces dernières peuvent ainsi intégrer la technologie d’OpenAI dans l’ensemble de leurs applications, sites Web, produits et services.
« Les modèles ChatGPT et Whisper sont désormais disponibles sur nos API, ce qui permet aux développeurs d'accéder à des fonctionnalités de pointe en matière de langage (et pas seulement de chat !) et de reconnaissance vocale » indique la firme. En clair, les développeurs peuvent désormais s’attendre à des résultats beaucoup plus rapides et pertinents lors de l’utilisation des deux modèles.
L’API ChatGPT
OpenAI a publié une famille de modèles ChatGPT, appelée gpt-3.5-turbo, qui est le même modèle que celui utilisé dans le produit ChatGPT. Au prix de 0,002 $ pour 1 000 tokens, soit l’équivalent de 750 mots, ce modèle est considéré comme meilleur pour de nombreux cas d'utilisation non liés au chat et « 10 fois moins cher que les modèles GPT-3.5 existants ». La firme indique que plusieurs testeurs ont ainsi migré de text-davinci-003 à gpt-3.5-turbo en n'apportant qu'une légère modification à leurs invites (prompt). Parmi eux, on retrouve Snap (créateur de Snapchat), Quizlet (une plateforme d'apprentissage), ou encore Shopify.
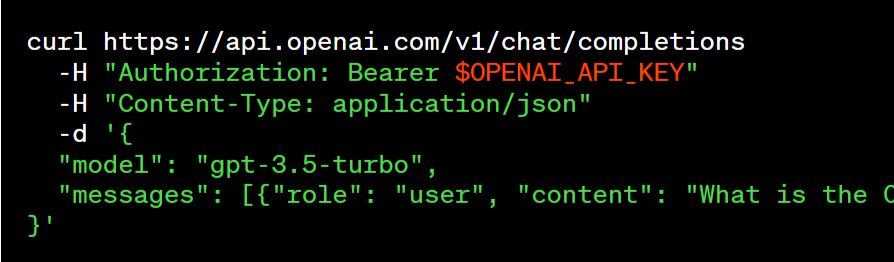
Les développeurs qui utilisent le modèle gpt-3.5-turbo auront donc la possibilité d’accéder au modèle stable et, lorsqu’ils le souhaitent, opter pour une version spécifique du modèle. OpenAI donne l’exemple de gpt-3.5-turbo-0301, qui sera pris en charge au moins jusqu'au 1er juin. Une version stable de gpt-3.5-turbo devrait arriver en avril.
L’API Whisper
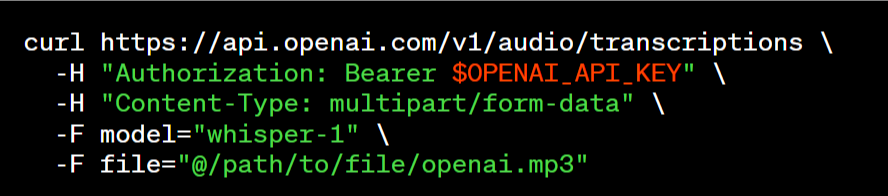
Whisper, le modèle de conversion de la parole en texte (speech to text) mis en libre accès en septembre 2022, profite également de cette vague de changements. « Nous avons désormais mis le modèle large-v2 à disposition via notre API, qui offre un accès pratique à la demande au prix de 0,006 $ / minute. En outre, notre pile de serveurs hautement optimisée garantit des performances plus rapides que celles des autres services » affirme la start-up.
Cette API est disponible par le biais de différents points d'accès aux transcriptions (transcription dans la langue source) ou aux traductions (transcription en anglais), et accepte une variété de formats (m4a, mp3, mp4, mpeg, mpga, wav, webm).
S’adressant aux développeurs, la firme indique avoir apporté des modifications concrètes à différents niveaux. Ainsi, les données soumises par le biais de l'API ne sont plus utilisées pour améliorer les services (y compris la formation des modèles), à moins que l’entreprise n'en décide autrement. Pour des raisons de sécurité, une politique de conservation des données par défaut de 30 jours a été mise en place pour les utilisateurs de l'API, avec des options de conservation plus stricte en fonction des besoins. L’examen préalable au lancement est par ailleurs supprimé et la documentation destinée aux développeurs est améliorée. Enfin, OpenAI précise qu’en ce qui concerne la propriété des données, « les utilisateurs sont propriétaires des données d'entrée et de sortie des modèles ».
Des instances dédiées sur Azure
Dans le même temps, OpenAI intr oduit des instances dédiées pour les utilisateurs qui souhaitent un contrôle plus approfondi de la version spécifique du modèle et des performances du système. Par défaut, les demandes sont exécutées sur une infrastructure de calcul partagée avec d'autres utilisateurs, qui paient par requête. Les API fonctionnent sur Azure et, avec les instances dédiées, les développeurs paient par période de temps pour une allocation d'infrastructure de calcul réservée au traitement de leurs demandes. Ainsi, les développeurs ont un contrôle total sur la charge de l'instance (une charge plus élevée améliore le débit mais ralentit chaque demande), la possibilité d'activer des fonctions telles que des limites de contexte plus longues et la possibilité d'épingler l'instantané du modèle.
Commentaire