")
En direct de San Francisco. Si une grande majorité des annonces de la conférence Next (du 29 au 31 aout à SF) ont porté sur la plateforme Vertex AI et sur l’assistant Duet AI, Thomas Kurian, CEO de Google Cloud, n’oublie pas la brique infrastructure essentielle « pour construire et entraîner les modèles d’IA qui intègrent de plus en plus de paramètres ». Dans ce cadre, le fournisseur a présenté plusieurs évolutions dans les instances dédiées à ces workloads.
Les TPU v5e inaugurent le multislice
En premier lieu, GCP dévoile les instances à base de TPU (tensor processing unit) v5e, la puce maison pour accélérer l’inférence et l’entraînement des modèles d’IA. Elle succède à la quatrième génération présentée en 2022 et qui avait été optimisée récemment avec l’usage de commutateurs à circuit optique. Dans le détail, chaque TPU v5e comprend un TensorCore (c’était deux sur les TPU 4) intégrant 4 MXU (Matrix Multiply Units), une unité vectorielle et une unité scalaire. La 5ème génération est disponible en Pod, comprenant 256 puces interconnectées et affichant une bande passante de 400 Tb/s pour des capacités de traitement pouvant atteindre 100 Pétaflops. Elles sont intégrées avec GKE (Google Kubernetes Engine), mais aussi Vertex AI et d’autres framework tels que PyTorch, TensorFlow and JAX.

Les Cloud TPU v5e sont officiellement disponibles. (Crédit Photo : JC)
Google Cloud propose les TPU v5e dans 8 configurations d’instances pouvant atteindre 250 puces sur 3 régions aux Etats-Unis (west 4, east 5et east 1). Le fournisseur met en avant le rapport performance/prix de ses puces, deux fois plus rapide pour la formation et pour l’inférence des LLM à prix équivalent. Il en profite aussi pour dévoiler la technologie multislice accessible en test qui offre la possibilité de combiner des dizaines de milliers de puces TPU v5e ou les anciennes puces TPU v4. Auparavant, les clients étaient limités à une seule tranche de puces TPU, ce qui signifiait qu'ils étaient plafonnés à 3 072 puces avec la TPU v4. Une tâche d’entraînement pourra ainsi mobiliser plusieurs tranches de TPU dans un seul Pod ou sur des tranches dans plusieurs Pods avec un simple parallélisme de données. Cette technologie a été utilisée pour former les LLM PaLM 2 et Imagen, précise la firme de Mountain View.
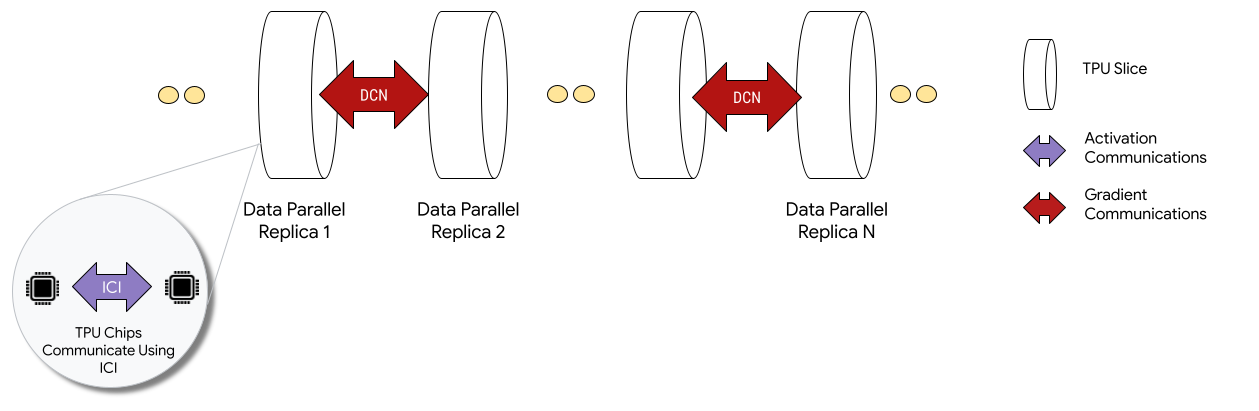
Avec le multislice, Google Cloud va pouvoir combiner des tranches de TPU v4 et v5e. (Crédit Photo : Google)
Un partenariat renforcé avec Nvidia
A côté des TPU, Google Cloud poursuit son partenariat avec Nvidia. Après VMware Explore à Las Vegas, son CEO Jensen Huang a fait le déplacement pour annoncer un renforcement de la collaboration avec le fournisseur de cloud dans le domaine de l’IA. Parmi les annonces faites, Google Cloud actualise ses instances A3 en adoptant les accélérateurs GPU H100 (les instances précédentes fonctionnaient avec des A100). Au menu, des performances multipliées par trois pour l’entraînement des modèles et une bande passante augmentée par 10. Les instances A3 disponibles en septembre comprend 2 processeurs Intel Xeon Scalable de 4ème génération, huit H100 par VM et 2 To de mémoire. Elles ont déjà séduit des start-ups dans l’IA comme Midjourney ou Anthropic. A noter que dans les prochaines semaines, les H100 de Nvidia seront accessibles sur la plateforme Vertex AI.

Thomas Kurian et Jensen Huang ont renforcé leur partenariat autour de l'IA. (Crédit Photo : JC)
Lors de la discussion entre Thomas Kurian et Jensen Huang, il est ressorti que Google Cloud sera parmi les premiers à avoir accès à son système DGX H200, basé sur la puce GH 200. Entrée en production au mois de mai dernier, cette dernière combine CPU (Grace) et GPU (Hopper). Le système taillé pour accélérer l’entraînement des grands modèles d’IA doit arriver à la fin de l’année et une déclinaison cloud (DGX Cloud) sera proposée par le fournisseur.
Google Distributed Cloud optimisé pour l’IA
Dernier étage d’annonces autour de l’infrastructure, la mise à jour de l’offre Google Distributed Cloud en l’adaptant aux workload IA. La solution de cloud hybride propose d'intégrer la pile logicielle de Google Cloud dans les datacenters des entreprises ou en mode edge à travers du matériel optimisé. Pour les datacenters, le système embarque des puces Intel Xeon Scalable de 4ème génération et des accélérateurs GPU A 100 de Nvidia. Si le fournisseur ne donne pas le nom de son partenaire hadware, le petit logo vert aperçu dans les allées de Next laisse penser qu’il s’agit de HPE. Pas de doute sur les configurations Edge intégrant des serveurs Edgeline du constructeur. Lors d'un entretien, Thomas Kurian, indique que "ces configurations peuvent trouver leur place dans le secteur du retail ou de la santé par exemple dans des hôpitaux pour analyser plus rapidement des radios avec des modèles pré-entraînés".

Google propose plusieurs facteurs de forme pour son offre de cloud hybride y compris à destination de l'edge. (Crédit Photo: JC)
Sur la partie IA, Google a présenté Vertex AI on GDC Hosted qui met à disposition des clients des modèles pré-entraînés sur différentes thématiques : la parole, la traduction, la reconnaissance optique de caractères… Ce service comprend par ailleurs des fonctionnalités comme Predictions pour connaître le résultat d'un modèle de machine learning entraîné ou Pipelines pour automatiser, surveiller et gérer les workflow ML. Concernant les bases de données, GDC prend en charge Alloy DB Omni dévoilée en mars dernier et en test. Il s’agit d’une version on prem de sa base de données entièrement managée AlloyDB (Database-as-a-Service, DBaaS), compatible avec PostgreSQL. Elle s’avère idéale pour les charges de travail transactionnelles et les données d'entraînement à l'IA en particulier en gérant les embbeding vector (des représentations numériques de mots ou de phrases dans le cadre du NLP).
Commentaire