")
Après avoir présenté les avancées de sa version 7.0 dans le traitement des big data, en septembre dernier, lors de la conférence Strata+Hadoop World NYC, Pentaho décrit une 2e salve d'évolutions sur sa plateforme d'intégration et d'analyse de données, attendue pour la mi-novembre en disponibilité générale. Ces nouvelles fonctions portent cette fois sur la phase amont de préparation des données et présentent l'originalité de s'adresser aux utilisateurs métiers. Ceux-ci vont pouvoir visualiser directement les données préparées par les équipes IT, « dès la phase d'ingestion, à partir de la plateforme de visualisation qu'ils utilisent déjà pour créer les rapports », nous a expliqué Ursula Radczynska, responsable des comptes Entreprise de Pentaho pour la France. Elle souligne l'intérêt de permettre aux utilisateurs de vérifier le plus tôt possible les données dans la chaîne de traitement, à tous les niveaux du pipeline. « Dans le fonctionnement actuel, l'utilisateur doit souvent attendre plusieurs jours pour pouvoir le faire ».
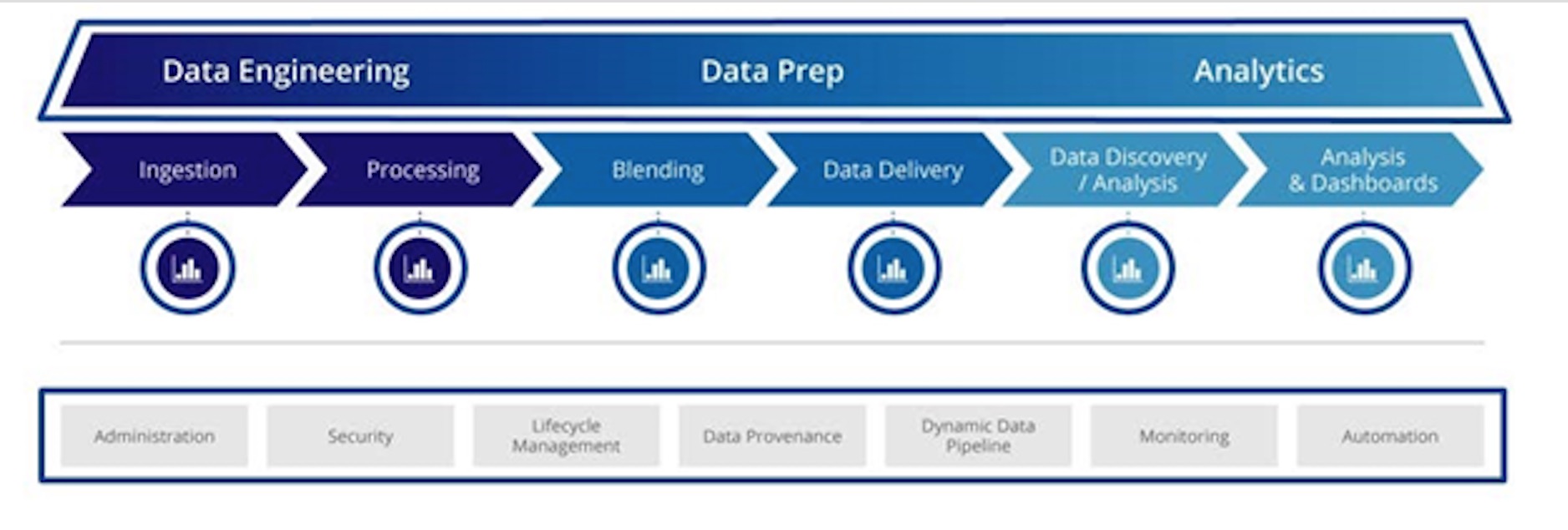
Les différentes étapes d'ingestion et préparation des données jusqu'à l'analyse (agrandir).
« L'idée, c'est aussi de rapprocher le monde de la IT et celui des métiers afin de permettre une meilleure collaboration et de pouvoir valider plus rapidement que l'informatique travaille sur les bonnes données », souligne Ursula Radczynska. Le fait de pouvoir les visualiser fera par exemple apparaître immédiatement l'absence d'informations sur une période donnée, ce que l'utilisateur métier saura très vite repérer. Par ailleurs, dans cette nouvelle version de la plateforme Pentaho, l'équipe IT peut mettre l'ensemble des données à la disposition des utilisateurs en leur donnant un accès direct aux différentes sources.
Accéder à Spark via SQL
D'autres nouveautés de la version 7.0 portent sur les fonctions de reporting. La plateforme permet maintenant de lancer l'élaboration d'un rapport et d'effectuer d'autres tâches dans l'intervalle, tout en suivant le statut d'avancement de création du rapport. Des indicateurs permettent ainsi de surveiller le déroulement des tâches volumineuses.
Quant aux évolutions liées au big data présentées en septembre dernier sur Strata+Hadoop World NYC, elles se résument en cinq points dont une intégration renforcée avec Spark. « On peut maintenant accéder plus facilement à Spark via SQL », pointe Ursula Radczynska. « Les ressources Hadoop sont chères et rares, il est donc intéressant de fournir des interfaces connues afin de pouvoir former des ressources moins expertes ». La version 7.0 apporte par ailleurs un fonctionnement étendu autour de l'injection de métadonnées, une meilleure gestion de la sécurité dans Hadoop, une intégration avec Kafka et, enfin, une prise en compte des formats d'échange de fichiers Avro et Parquet. La plateforme de Pentaho s'appuyant sur les différentes solutions de stockage du marché, « nous sommes bien placés pour voir quels sont les formats de stockage et de communication qui sont le plus utilisés », souligne Ursula Radczynska. D'ailleurs, souligne-t-elle, « nos clients nous demandent de les conseiller sur l'architecture globale ».
Commentaire