")
Plus de 4 ans après le désastre du robot de tchat Tay de Microsoft, le MIT est également tombé dans le piège de l'IA devenue raciste. L'établissement a ainsi annoncé avoir mis hors ligne un jeu de données sur lequel une IA mal entraînée a été adossée avec pour conséquence de multiplier les termes racistes, misogynes, sexistes et offensants pour qualifier un immense volume d'images. « Il a été porté à notre attention que l'ensemble de données Tiny Images contient des termes dérogatoires en tant que catégories et images offensantes. C'était une conséquence de la procédure de collecte de données automatisée qui reposait sur des noms de WordNet. Nous en sommes très préoccupés et nous nous excusons auprès de ceux qui pourraient avoir été touchés », explique le MIT.
A l'origine le MIT a créé Tiny Images, un dataset de 79,3 millions d'images extraites de Google Images réparties en 75 000 catégories dans une résolution minuscule de 32x32 pixels. Une version allégée de 2,2 millions d'images, consultable à partir du site web du laboratoire d'informatique et d'intelligence artificielle du MIT (CSAIL) pour laquelle une visualisation de données a été adossée, a par ailleurs été conçue. « Le jeu de données a été créé en 2006 et contient 53 464 noms différents, directement copiés à partir de Wordnet. Ces termes ont ensuite été utilisés pour télécharger automatiquement les images du nom correspondant à partir des moteurs de recherche Internet de l'époque en utilisant les filtres disponibles pour collecter les 80 millions d'images ; les versions originales à haute résolution n'ont jamais été stockées », explique le MIT.
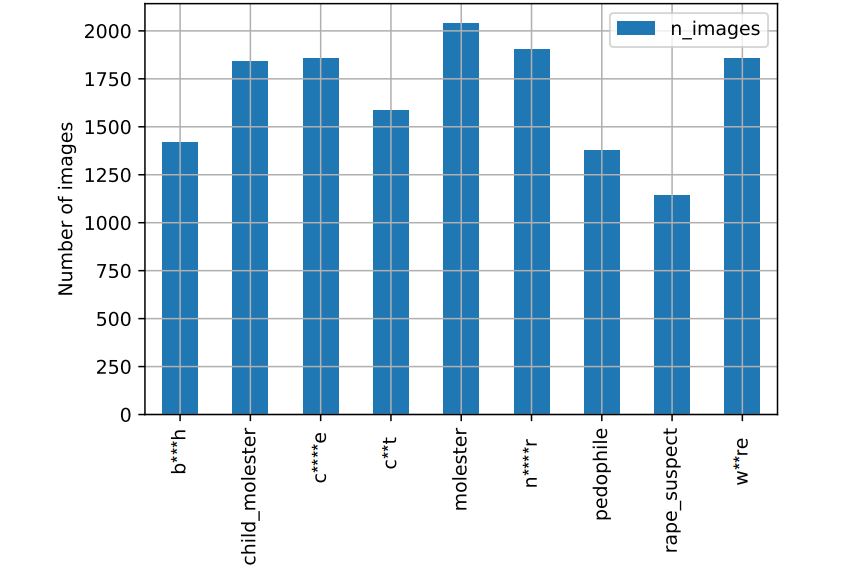
Répartition des images par catégories offensantes liées aux femmes. (crédit : D.R.)
Des milliers d'images étiquetées avec des insultes racistes et des termes péjoratifs
Cette énorme collection de photos utilisait des étiquettes pour décrire ce qui se trouvait dans les photos et un réseau de neurones a été implémenté pour associer automatiquement des modèles de photos à des étiquettes descriptives. Problème : lorsque l'apprentissage n'est pas suffisamment cadré, des corrélations douteuses peuvent arriver comme cela a été le cas pour le MIT. Vinay Prabhu, directrice scientifique chez UnifyID et Abeba Birhane, doctorante à l'University College Dublin en Irlande, se sont penchées sur la base de données du MIT et ont ainsi découvert des milliers d'images étiquetées avec des insultes racistes sur les noirs et les asiatiques, et termes péjoratifs utilisés pour décrire les femmes. Le problème vient du fait que le moteur d'apprentissage automatique utilisé n'a pas été correctement paramétré, avec pour conséquence dommageables d'identifications et de classification d'images, comme par exemple étiqueter des femmes en tant que « prostituées ».
« Les préjugés, les images offensantes et nuisibles et la terminologie désobligeante aliènent une partie importante de notre communauté - précisément ceux que nous nous efforçons d'inclure. Il contribue également aux biais préjudiciables dans les systèmes d'IA formés à ces données. De plus, la présence de ces images biaisées nuit aux efforts visant à favoriser une culture d'inclusion dans la communauté de la vision par ordinateur. C'est extrêmement malheureux et va à l'encontre des valeurs que nous nous efforçons de défendre. »
Cela reflète très certainement la mentalité des utilisateurs. Recadrer l'apprentissage pourquoi pas, mais c'est peut-être aussi une occasion d'observer à quel internet et la société en général sont oppressantes.
Signaler un abusC'est quasiment imagenet roulette.
Signaler un abusTout les hyponymes de personne ont été supprimés d'imagenet pour quasiment les mêmes raisons.
Ça ne pouvait que bugger
Malheureusement l'IA est logique par nature #statistiques
Signaler un abus