")
L'année 2023 a été marquée par la montée en puissance des modèles d'IA générative se présentant comment ouverts. Mais que signifie ce qualificatif dans le contexte de l'intelligence artificielle ? C'est à cette question complexe que tente de répondre une étude de deux chercheurs du Centre pour les études sur le langage de l'université de Nimègue, aux Pays-Bas. Ceux-ci identifient 14 critères différents permettant de définir le degré d'ouverture d'un modèle. Un ensemble d'attendus, qui vont des jeux de données d'entraînement, aux méthodes d'accès en passant par la documentation et le licensing, que les quelque 45 modèles prétendument Open Source que les deux chercheurs passent au crible sont loin de respecter.
« Bien que le terme open source soit largement utilisé, de nombreux modèles sont au mieux "open weight" et de nombreux fournisseurs cherchent à échapper à l'examen scientifique, juridique et réglementaire en masquant des informations sur les données de formation et de fine-tuning », écrivent Andreas Liesenfeld et Mark Dingemanse, les auteurs. Le terme "open weight" masque une définition plus restrictive de la transparence que celle de l'open source, puisque les 'poids' en question (weight) se réfèrent aux pondérations d'un réseau de neurones résultant des cycles de formation sur les données. Des pondérations qui ne sont ni lisibles par l'homme ni déboguables. Le terme 'open weight' fait donc référence à la disponibilité de ces pondérations pour utilisation ou modification. Mais laisse dans le flou bien d'autres aspects de la construction du modèle, soulignent les auteurs de l'étude, qui y voient une forme « d'openwashing », en référence au greenwashing.
Meta, Google, Microsoft et Mistral parmi les mauvais élèves
Classés en trois familles (disponibilité, documentation et accès), les 14 critères laissent ainsi apparaître des différences flagrantes entre des modèles se présentant tous comme ouverts. Sur les 40 générateurs de texte étudiés, certains frôlent le statut de modèle totalement ouvert, comme OLMo Instruct, d'AllenAI, BloomZ ou AmberChat, de LLM360. « Les organisations à l'origine de ces systèmes se sont donné beaucoup de mal pour mettre à disposition les données de formation, le code, les pipelines de formation et la documentation », soulignent les auteurs de l'étude.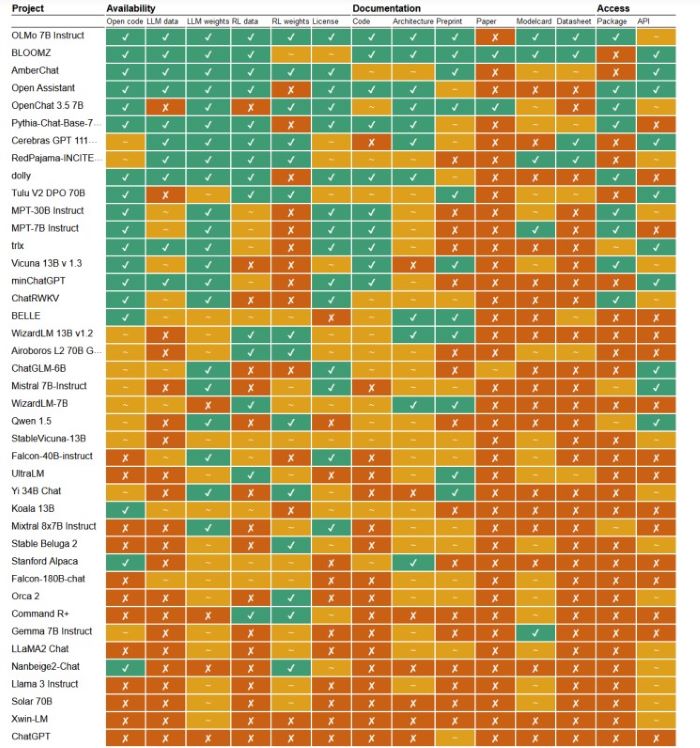
L'évaluation d'une quarantaine de modèles générateurs de textes. Certains, se revendiquant ouverts, présentent des caractéristiques proches du très opaque ChatGPT.
Un tiers des modèles se contentent de dévoiler leurs pondérations (open weight), « mais partagent peu, voire aucun détail concernant d'autres parties du système ». La conclusion des auteurs est sans appel : « comparés à la philosophie très fermée du ChatGPT d'OpenAI, certains de ces systèmes sont à peine plus ouverts. » Parmi ces mauvais élèves de la classe, on retrouve tous les grands acteurs issus du monde commercial dont Meta, Google, Cohere, Microsoft et Mistral. Llama 3 de Meta ne coche ainsi aucun des 14 critères définis par les chercheurs. Mistral-7B-Instruct de la société éponyme n'en remplit que trois.
50 nuances d'open source
« Le manque d'ouverture concernant les données d'entraînement est particulièrement inquiétant. La plupart des modèles de la moitié inférieure [du classement fourni dans l'étude, NDLR] ne fournissent aucun détail sur les jeux de données en dehors de descriptions très génériques, manifestement afin d'échapper à tout examen sur le plan juridique », observent Andreas Liesenfeld et Mark Dingemanse. Concernant les générateurs d'images, le constat est encore plus rapide. Un seul modèle remplit la plupart des critères - Stable Diffusion -, tandis que les autres en cochent au mieux deux ou trois.
L'étude des deux chercheurs met aussi en évidence le caractère spécifique de l'ouverture des LLM. « L'ouverture dans l'IA générative est nécessairement composite (composée de plusieurs éléments) et graduelle », plaident les auteurs de l'étude, pour qui s'appuyer sur une ou quelques caractéristiques spécifiques, telles que les caractéristiques de l'accès à la technologie ou la licence, pour déclarer un modèle ouvert ou non serait une erreur. Les deux chercheurs plaident pour un système de scores ou de labels reflétant le degré d'ouverture de chaque LLM.
A lire sur le même sujet :
- 10 points à surveiller avec l'IA générative open source
Commentaire