")
Les plateformes de traitement et d’analyse de données unifiées, telles que la solution cloud collaborative de Databricks, sont de plus en plus sollicitées à grande échelle par les entreprises pour leurs projets analytiques et d’apprentissage machine. Si les défis de sécurité sont simples à résoudre pour des équipes et des jeux de données réduits, ils se complexifient quand il faut mettre en production de multiples applications et les passer à l’échelle, qui plus est dans des environnements multi-clouds. « Dans de nombreux cas, nos clients ont des milliers de personnes qui utilisent notre produit à travers différentes business units pour une variété de cas d’usage différents, tous impliquant d’accéder à des classifications de données diverses, privées, sensibles ou publiques », explique sur son blog l’éditeur californien fondé en 2013 par les créateurs d’Apache Spark, Delta Lake et MLflow. Parmi ses dernières évolutions en date, Databricks a renforcé sa sécurité, étendu ses fonctions d’administration des utilisateurs et ajouté des capacités d’automatisation.
Rappelons que la plateforme Unified Data Analytics de Databricks se compose d’une couche de stockage (Delta Lake) pour fiabiliser les data lakes, qu’elle fournit des pipelines de données s’appuyant sur Spark, des notebooks collaboratifs, des environnements de machine learning, MLFLow pour gérer le cycle de vie des modèles ML, ainsi que des services d’administration, de sécurité et des intégrations avec les écosystèmes CI/CD (intégration et livraison continues).
Des contrôles de sécurité natifs cloud
Hébergée sur Microsoft Azure ou AWS, la solution de Databricks permet aux entreprises de centraliser sur une seule plateforme l’ensemble de leurs données et l’accès des utilisateurs qui les exploitent, avec une sécurité qui s’appuie sur les contrôles fournis par les clouds publics, ceux-ci étant nativement conçus pour être déployés à l’échelle. « Plutôt que de répliquer ou reconstruire ce qui a été fait localement, nous profitons des règles de sécurité et des ressources que propose le cloud », nous a expliqué Nicolas Maillard, directeur Field Engineering de Databricks pour les régions Central & SEMEA. Ainsi, la plateforme s’intègre avec les gestions des identités et des accès (IAM) natifs et utilise les services de clés de chiffrement des données.
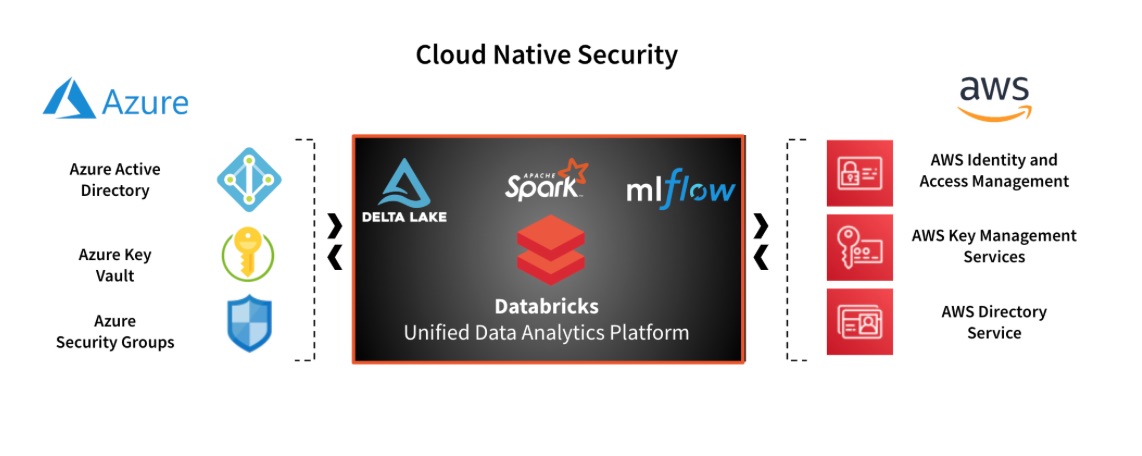 Databricks tire parti des services de sécurité de Microsoft Azure et Amazon Web Services. (Crédit : Databricks)
Databricks tire parti des services de sécurité de Microsoft Azure et Amazon Web Services. (Crédit : Databricks)
Le mois dernier, l’éditeur basé à San Francisco a ajouté à sa sécurité des clés de chiffrement révocables appartenant aux clients et l’utilisation de réseaux privés pour leurs clusters Databricks dans le cloud. « Les clients peuvent ainsi gérer leurs clés d’encryption, les créer, les révoquer, les distribuer, nous les portons nativement dans le cloud », souligne Nicolas Maillard. Les entreprises peuvent aussi mettre en oeuvre les réseaux Azure Private Link ou AWS privateLink. Le trafic entre les utilisateurs de la plateforme, les notebooks et les clusters qui traitent les requêtes est ainsi chiffré et transmis sur le réseau privé du fournisseur cloud où la plateforme est déployée, inaccessible depuis le monde extérieur.
Une visibilité sur la consommation des ressources cloud
Databricks a également fait évoluer les outils d’administration de sa plateforme. « Aujourd’hui, avec l’arrivée de nombreux clients et l’extension de la plateforme chez les clients existants, nous voyons de nouveaux usages apparaître, comme la création de zones de travail pour séparer logiquement les équipes », expose le directeur Field Engineering Central & SEMEA. Ces zones de travail peuvent concerner différentes zones géographiques, ou différents clouds. Cela peut aussi permettre de comprendre quels types de données et de ressources sont consommés. « Il s’agit vraiment d’une notion d’administration et de gouvernance au sens fonctionnel des choses et on s’est attaché ici à donner une transparence complète sur ce qui se passe », indique Nicolas Maillard.
Jusque-là, un certain nombre d’environnements étaient définis au départ. « Nous avons désormais rendu extrêmement simple, en quelques clics, de pouvoir créer d’autres zones virtuelles de travail, d’autres environnements, de façon complètement naturelle, au fur et à mesure de la vie des plateformes. Cela donne la capacité de les rattacher à des notions de groupes de consommation de ressources cloud pour avoir une compréhension granulaire de qui consomme quoi et de pouvoir le réattribuer à des projets ou à des groupes dans l’entreprise ». Il est aussi possible de rattacher des utilisateurs de façon temporaire à des groupes et de permettre à des utilisateurs de travailler sur plusieurs projets, en les extrayant des projets une fois leur intervention terminée.
Automatiser le cycle de vie des données et du ML
Sur la partie mise en production des projets analytiques et de machine learning, Databricks a par ailleurs renforcé ses capacités d’automatisation. « Lorsqu’il y a des centaines de projets, ou beaucoup plus, et de workspaces en place au même moment, comment permet-on de construire un système scalable et répétable, pour pouvoir déployer l’ensemble de ces applications et de ces modèles ML un peu partout sans devoir repasser à chaque fois par la configuration manuelle. Depuis le début, Databricks s’est attaché à tout rendre API first », rappelle Nicolas Maillard. « Tout ce qui est visible dans notre application est une API sur laquelle nous proposons un service web ». Celles-ci sont maintenant tournées vers les outils de livraison continue CI/CD (Terraform, Jenkins, MLflow…) pour que les équipes devops puissent automatiser le cycle de vie des données et du machine learning, depuis la prise en charge de git jusqu’au monitoring de l’infrastructure et des applications.
Spécialiste de Spark, Databricks est à l’origine entré dans les entreprises par ce biais. Il a par la suite étendu sa base d'utilisateurs en dehors de Spark sur l’ingénierie de données et l’automatisation du ML et des applications, sujets auxquels l’éditeur consacrera un certain nombre de sessions lors de son événement virtuel Spark+AI Summit (SAIS), organisé du 22 au 26 juin prochain.
(màj) Hackathon for social good
A l'occasion du Spark+AI Summit, Databricks organise le « hackathon for social good » en mettant l’accent sur trois des problématiques les plus délicates du moment : la pandémie Covid-19 (en associant des jeux de données publiques pour mieux comprendre la situation ou apporter des solutions aux problèmes logistiques), le changement climatique et le changement social au sein d’une communauté. Pour utiliser les données sur le Covid-19, la version Community Edition de sa plateforme permet d’accéder librement à divers jeux de données.
Les candidatures pour participer à ce hackathon pourront être reçues jusqu’au 29 mai 2020. Les trois équipes lauréates, qui seront annoncées lors du SAIS, pourront faire des dons à l’organisation caritative de leur choix (20 000 $ de dons pour le 1er prix, 10 000 $ pour le 2e et 5 000 $ pour le 3e, à attribuer à l’organisation choisie). Les équipes gagnantes recevront aussi une formation gratuite et un laissez-passer pour le Spark +AI.
Commentaire