")
La préparation des données pour les applications analytiques reste en grande partie un processus manuel assez long pour les équipes IT spécialisées. Pour simplifier la conception des pipelines d’ETL, qui demande un travail très granulaire pour définir comment transformer les données et tester ces manipulations, Databricks vient de livrer en préversion le framework Delta Live Tables. Ce service cloud a été présenté à l’occasion de la conférence Data+AI Summit 2021. Il vient prendre en charge l’essentiel des transformations opérées sur les données. Plutôt que de définir les pipelines avec les différentes tâches Spark, l'utilisateur fournit à Delta Live Tables le schéma cible qu'il veut obtenir. Le service se base sur ce schéma cible pour définir chaque étape de traitement. On peut préciser la qualité des données attendue et spécifier comment gérer ce qui ne répond pas à ces attentes, explique Databricks dans sa documentation.
L’éditeur californien, spécialiste de Spark, renforce d’autre part ses capacités de gouvernance des données à travers l’annonce de Unity Catalog. A partir d’une interface centralisée, la solution permettra une gouvernance granulaire de l’ensemble des données, structurées et non structurées, déversées dans les datalakes, en prenant en compte le multi-cloud et les catalogues existants. Ce modèle de gestion centralisée est basé sur SQL. L’interface de Unity Catalog va simplifier la découverte, l’audit et la sécurisation de l’accès aux données en apportant des fonctions de data lineage, des politiques de sécurité basées sur les rôles, des tags au niveau des tables et colonnes… directement sur le lakehouse.

Avec Unity Catalog, les administrateurs de base de données peuvent accorder des permissions sur des vues ou des colonnes en utilisant SQL. (Crédit : Databricks)
Unity Catalog s’appuie sur le protocole Delta Sharing que Databricks promeut désormais pour le partage sécurisé des données entre les entreprises. Ce protocole fait l’objet d’un projet open source, confié à la fondation Linux.
Gérer le cycle de vie ML en mode collaboratif
Pour les data scientists, Databricks fait par ailleurs évoluer son offre de conception, expérimentation et mise en production de modèles d’apprentissage machine. Sur sa conférence Data+AI Summit 2021, l'éditeur a annoncé la plateforme Databricks Machine Learning qui s’appuie de façon native sur son architecture de lakehouse. Celle-ci apporte une expérience collaborative pour créer, entrainer, déployer et gérer des modèles ML.
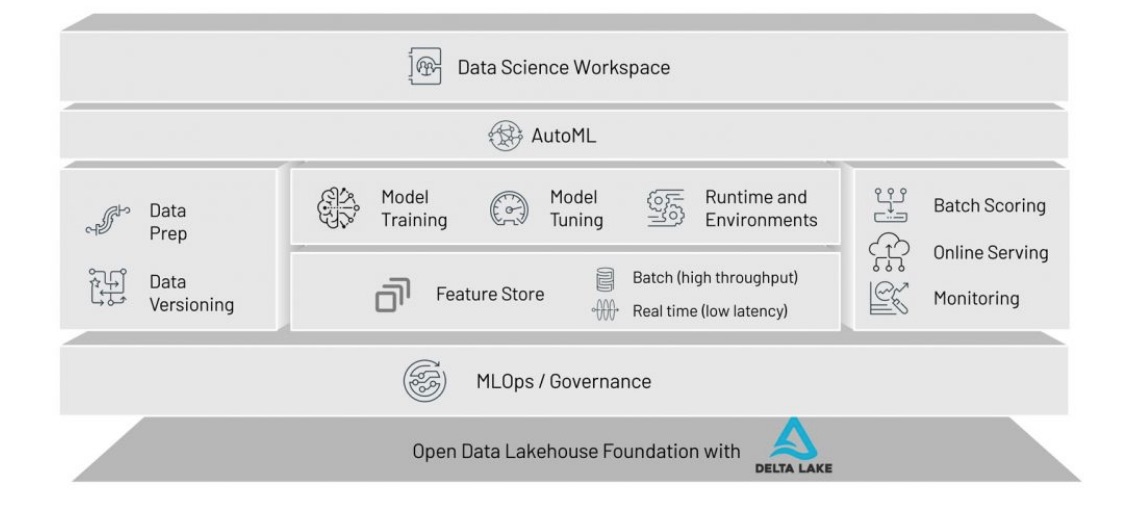
Databricks ML prend en charge tout type de données à n'importe quelle échelle. (Crédit : Databricks)
Parmi les avancées, l’offre apporte AutoML et Feature Store. AutoML vient automatiser une grande partie des tâches répétitives manuelles des data scientists. Il fournit à ces derniers une transparence complète sur le fonctionnement des modèles dont ils peuvent reprendre le contrôle à tout moment, explique Databricks. Ces expériences AutoML sont intégrées au reste de la plateforme Lakehouse, y compris MLflow. Quant à Feature Store, il permet de partager et réutiliser les caractéristiques utilisées par les modèles de ML. « C’est une notion de warehouse pour la data science et les modèles ML », nous a décrit Nicolas Maillard, directeur senior architecte solution de Databricks pour les régions Central & SEMEA. Cela permet de cataloguer ces caractéristiques, de les accrocher aux différents modèles, aux pipelines qui ont servi à les créer, aux différentes équipes qui s’en servent, et d’obtenir des explications sur la façon dont on a choisi de les comprendre. Databricks Machine Learning est disponible en préversion.
Commentaire