")
Mistral AI ne se repose pas sur ses lauriers. Après avoir réussi à lever 600 M€ - et dépassant au passage les 6 milliards d'euros de valorisation théorique - la start-up française a multiplié depuis quelques mois les lancements de modèles de langage dont Mixtral 8x22B ou encore Codestral. Ce dernier, spécialisé sur la génération de code, connait déjà une descendance avec Codestral Mamba. Alors que son prédécesseur s'appuyait sur 22 milliards de paramètres, le petit dernier est un 7B et repose donc sur l'architecture de modèle de langage Mamba conçu pour remédier à certaines limites des modèles de transformers tout particulièrement dans le traitement des longues séquences. Les cas d'usage sont variés, incluant aussi bien la complétion ou la génération de code que de la détection et résolution de bug.
Selon la start-up française, Codestral Mamba a l'avantage d'une inférence en temps linéaire et la possibilité théorique de modéliser des séquences de longueur infinie, et permet aux utilisateurs de l'utiliser de manière intensive et d'obtenir des réponses rapides, quelle que soit la longueur de l'entrée. "Cette efficacité est particulièrement pertinente pour les cas d'utilisation de la productivité du code c'est pourquoi nous avons formé ce modèle avec des capacités de code et de raisonnement avancées, ce qui lui permet d'être aussi performant que les modèles basés sur les transformateurs SOTA", explique Mistral AI. Au regard des résultats d'un comparatif mené par Mistral AI, Codestral Mamba arrive apparemment à se démarquer dans de nombreux tests.
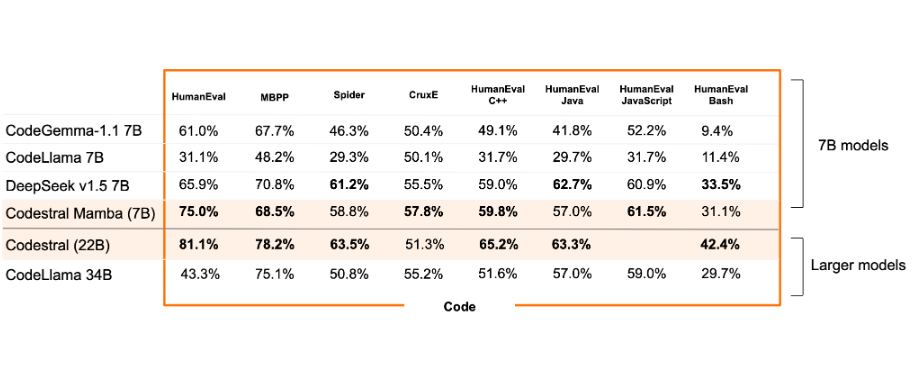
Comparatif des performances de Codestral Mamba 7B et Codestral 22B face à d'autres LLM de génération de code du marché. (crédit : Mistral AI)
Un déploiement possible via TensorRT-LLM et bientôt llama.ccp
Codestral Mamba a été testé avec des capacités de récupération en contexte maximale de 256k tokens. Contrairement à son grand frère, Codestral Mamba 7B n'est pas proposé en licence MNPL ou commerciale, mais uniquement sous Apache 2.0 à des fins de test et de recherche, ce qui veut dire que son code peut être modifié et partagé librement sans aucune contrainte. Ce modèle, disponible sur Hugging Face, peut être déployé en utilisant le SDK mistral-inférence, qui s'appuie sur les implémentations de référence du dépôt GitHub de Mamba, mais aussi via TensorRT-LLM et bientôt llama.cpp.
En parallèle de Codestral Mamba, Mistral AI a par ailleurs aussi annoncé Mathstral 7B, un modèle de langage spécifiquement conçu pour du raisonnement mathématique et la découverte scientifique. Son lancement intervient quelques mois après celui d'Orca-Math de Microsoft sur base Mistral 7B.
Commentaire