")
En direct de Las Vegas. L’IA continue d’alimenter les discours des acteurs de l’IT. Oracle n’échappe pas à cette règle à l’occasion de son évènement annuel qui se déroule à Las Vegas (du 9 au 12 septembre 2024). Lors de la première journée, Safra Catz, CEO d’Oracle a donné la parole à des clients sur ce sujet pour connaître leur avis. Bertrand Gavgani, DSI de BNP-Paribas a expliqué que les « plus grands défis sur l’IA aujourd’hui sont le passage à l’échelle et d’avoir les bons cas d’usage ». De son côté, la CIO de la CIA (Central Intelligence Agency) La’Naia Jones rappelle « la data est un élément clé de l’IA. Pour nous, il est important d’avoir les données les plus qualifiées pour nos différentes missions et la création d'applications ». Le décor est donc planté pour les annonces de l'éditeur sur l’IA et en particulier à l’attention des développeurs et des administrateurs de base de données.
GenDev, un facilitateur de création d’applications IA
En matière de développement, le fournisseur dévoile GenDev que Juan Loiaza, vice-président en charge des bases de données critiques définit comme « une infrastructure de données centrée sur l’IA pour aider les développeurs à créer leurs applications ». Il part du principe que les programmeurs sont confrontés à trois problèmes, « les dépendances généralisées dans les applications rendent leur création et leur évolution difficiles, le volume important de code rend difficile la compréhension, la vérification et la maintenance de l'application. Et enfin, la robustesse (confidentialité, cohérence, …) exigée par les entreprises nécessite de l’intégrer dans l’ensemble de l’application ».
Avec DevGen, Oracle propose notamment de lier les bases de données relationnelles avec les formats de données JSON. (Crédit Photo: JC)
Pour remédier à ces problématiques, Oracle combine plusieurs technologies dont Database 23ai présentée en mai dernier. Celle-ci comprend la recherche vectorielle qui relie les données structurées contenues dans les bases de données relationnelles aux données non structurées (image, texte, …) sous forme de vecteurs. Ceux-ci stockent le contenu sémantique des documents, images ou autres dans la base de données relationnelles. Dans GenDev, elle se voit adjoindre la fonctionnalité JSON Duality Views qui fait le lien entre les bases de données relationnelles et les formats de données JSON. Ce point est important pour Juan Loiaza, car les bases de données JSON ne supportent pas le partage de données et ont tendance à les dupliquer. « GenDev sépare le format d’accès à la donnée du format de stockage de la donnée pour générer un format normalisé », explique-t-il.
Heatwave s’enrichit pour la GenAI
Dans le portefeuille d’Oracle, la firme mise aussi sur Heatwave, une version managée de sa base de données et ses services analytiques fonctionnant sur OCI. Cette offre comprend plusieurs modules qui sont mis à jour pour l’IA générative. Ainsi, Heatwave GenAI présentée en juin dernier comprend maintenant des capacités de traitement par lots de l'inférence sur les LLM. Cette fonction vise à aider les développeurs à améliorer les réponses des applications en exécutant plusieurs requêtes simultanément, plutôt qu'une seule à la fois. Le support de plusieurs langues apporte à Heatwave GenAI la capacité d’effectuer des recherches de similarité sur des documents dans 27 langues différentes lors du développement d'applications. On peut ajouter la prise en charge de l’OCR pour intégrer le contenu numérisé dans l’entraînement des applications ou le support de JavaScript.
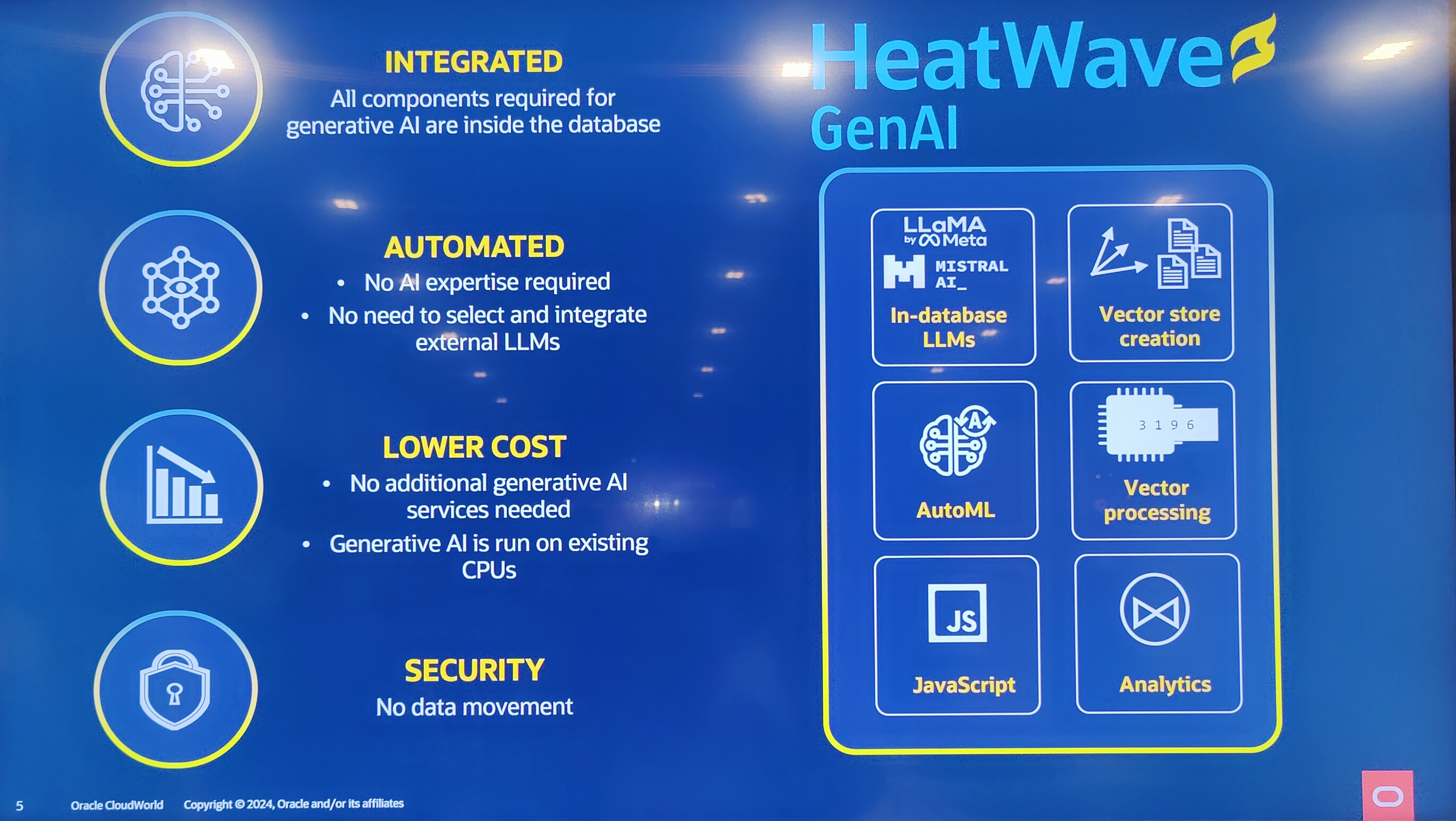
Heatwave GenAI s'étoffe progressivement avec des fonctionnalités supplémentaires. (Crédit Photo: JC)
Heatwave MySQL, le service managé d'accélération des requêtes OLTP et analytiques, est également mobilisé sur la GenAI. Oracle ajoute un optimiseur d’hypergraphe (structure généralisée de données dans laquelle une arête peut relier un nombre quelconque de sommets) pour optimiser la performance des requêtes complexes. Le fournisseur propose par ailleurs une intégration d’OCI Ops Insights pour connaître et surveiller l’état de santé des bases de données (problème de performance, de planification des ressources. Enfin, une fonction d’ingestion massive de données accélère le chargement des données et réduit la mobilisation des ressources pour leurs analyses. De son côté, Heatwave AutoML (apparu en 2023) dédié à l’entraînement de modèles de machine learning, accueille des modèles de taille plus importante et se dote d’une capacité de détection des dérives sur les réponses des modèles. Enfin, Heatwave Lakehouse (présentée en 2022) est maintenant capable d’écrire les résultats dans le stockage objet et de diffuser les modifications de manière incrémentale dans les tables sans avoir besoin de les recharger. Par contre rien n’a été dit sur la prise en charge des tables Apache Iceberg pourtant adoptées par la plupart des concurrents comme Snowflake ou Databricks.
Commentaire