
")
Avec son projet open source Omnia, Dell s’est attelé à simplifier la gestion des charges de travail associées au calcul haute performance, dans des environnements où des clusters de machines équipées d’accélérateurs graphiques opèrent ensemble comme un supercalculateur. Si les applications exécutées sur ces modèles d’architecture portent sur les domaines d’investigation classiques du HPC (compréhension des changements climatiques, recherche médicale et pharmaceutique, conception industrielle, simulations multiples…), ils sont aussi exploités pour l’analyse de données et pour le développement de modèles d’apprentissage machine. Leur mise en place et leur administration mobilisent fortement les ressources d’équipes IT, oeuvrant parfois séparément au sein des plus grandes entreprises pour bâtir divers clusters pour différents types de charges de travail, exposait Dell dans un billet il y a quelques mois. Avec Omnia, l’objectif est de faciliter le déploiement des configurations au sein d’infrastructures consolidées, en utilisant des logiciels open source dans le domaine du HPC, de l’IA et de l’analyse de données. Le tout fourni sous la forme de playbooks Ansible pour automatiser la succession des tâches à exécuter.
Omnia a été développé par le Dell Technologies HPC & AI Innovation Lab, en collaboration avec Intel et avec le support de la communauté HPC, dont le centre de recherche en informatique de l’Université d’Arizona (ASU). Il permet de créer un ensemble flexible de ressources pour répondre aux demandes diversifiées des charges de travail HPC, IA et analytiques. Les différents playbooks Ansible accélèrent le déploiement de workloads convergés en créant des clusters avec Kubernetes ou Slurm, ou bien avec les deux, en utilisant différents frameworks, services et applications. Omnia installe les logiciels à partir de sources variées dont les référentiels standards CentOS et ELRepo, Helm, du code source. Bientôt à partir de référentiels OpenHPC et OperatorHub. « A chaque fois que c’est possible, Omnia s’appuie sur des projets existants plutôt que de réinventer la roue », explique Dell sur GitHub. Pour l’analyse de données, ce sera Cassandra, Rapids, Apache Spark, R et Jupyter, pour l’AI, Kubeflow, Tensorflow, Nvidia Drive, Clara et Metropolis…, pour le HPC, Scalasca, PETSc, FFTW, HDF, Lmod.
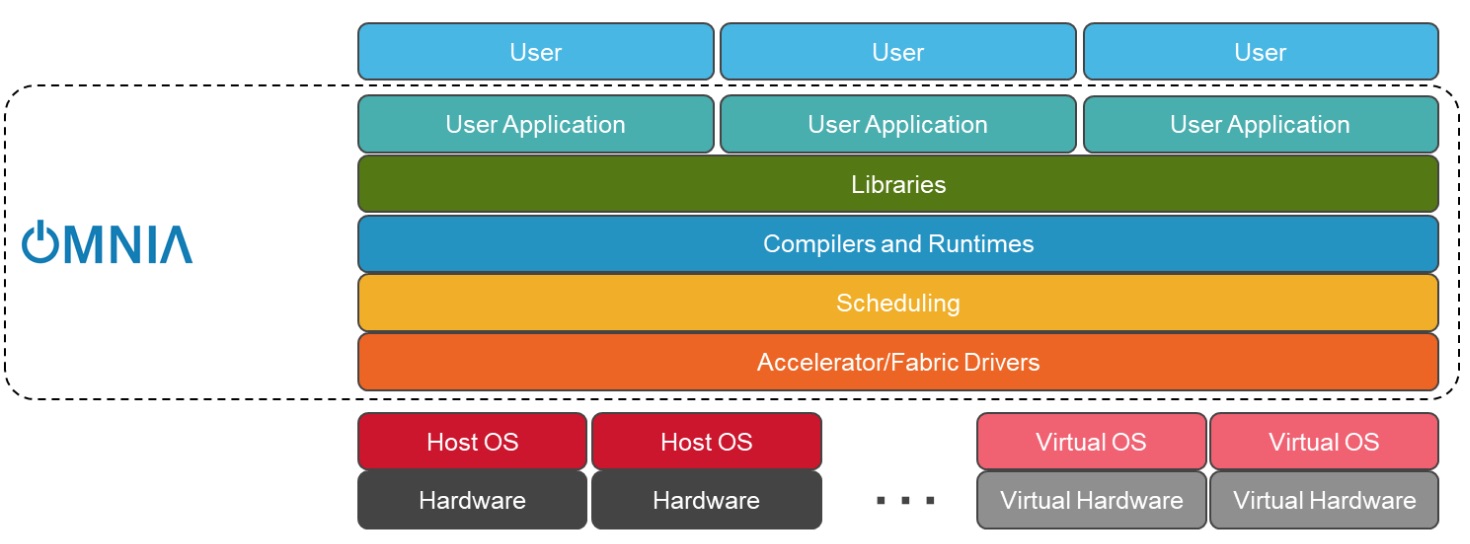
La pile de déploiement Omnia pour Slurm. (Crédit : Dell Technologies)
Bientôt le support de VMware pour des modèles de cloud hybride
En fonction du cas d’usage (simulation HPC, réseaux neuronaux pour l’IA, traitement d’analyse en mémoire), Omnia installe la configuration logicielle adaptée, en parvenant ainsi à réduire considérablement les temps de déploiement (de quelques semaines à quelques minutes), explique Dell. Dans un communiqué, Douglas Jennewein, directeur senior du centre de recherche de l’ASU, souligne l’intérêt d’avoir travaillé sur ce projet « qui va simplifier le déploiement et la gestion de ces charges de travail mixtes complexes, chez ASU et pour l'ensemble du secteur de l'informatique de pointe. »
La prochaine étape du projet porte sur le support des environnements VMware, en particulier Cloud Foundation, Cloud Director et vRealize Operations, pour apporter des modèles de cloud hybride pour les calculs haute performance exigeants, avec un accès aux ressources HPC dans le cadre de services à la demande proposés avec R Systems. Dell cite ici l’exemple de l’industriel Mercury Marine, spécialiste de la propulsion marine. En plus de ses propres systèmes de calcul, celui-ci recourt aux services HPC à la demande pour effectuer des simulations hydrodynamiques et a pu ainsi réduire à deux heures (contre deux jours auparavant) l’accès à ces ressources de calcul. Les serveurs Dell EMC PowerEdge R750, R750xa et R7525 utilisés pour ces applications intègrent maintenant des options GPU Nvidia A30 et A10 Tensor Core.
Commentaire