
 succédant aux puces Hooper (à droite). (Crédit Nvidia),")
Un peu avant sa conférence GTC (GPU Technical Conference ) du 18 au 21 mars 2024, de nouveau à San José après plusieurs éditions en ligne, Nvidia a dévoilé lors d’un prébriefing à la presse son architecture GPU Blackwell (exploitée sur la carte B200), qui vient succéder à Hopper (H100/H200), et des systèmes HPC DGX GB100 et GB200 qui offrent des gains de performance significatifs par rapport à l'ancienne génération. Il s’agit de la septième et de la plus impressionnante génération de GPU pour datacenter du fournisseur de Santa Clara. Cette vague de GPU dédié au calcul intensif a démarré au milieu des années 2000, mais a vraiment décollé avec le lancement des accélérateurs K10 et K20 (sur base Keppler) en mai 2012. Depuis, Nvidia a travaillé sur la progression du nombre de transistors dans ses GPU, sur l’emballage et la finesse de gravure des puces (avec TSMC), sans oublier la conception de moteurs mathématiques vectoriels et matriciels, l'amélioration de la précision des calculs en virgule flottante et enfin l'augmentation de la capacité mémoire et de la bande passante.
L’architecture Blackwell, en hommage au pionnier américain des statistiques et des mathématiques David Harold Blackwell, reprend les travaux initiés avec les plateformes Amper et Hopper, mais à un niveau supérieur avec plus de fonctionnalités, plus de flexibilité et plus de transistors. Toujours en quête d’excellence, Nvidia a ainsi amélioré la conception de ses puces où chaque élément est destiné à augmenter les performances dans une charge de travail spécifique ou à supprimer un goulot d'étranglement. Gravé en 4 nm chez TSMC (une version affinée du procédé utilisé pour Hooper), le GPU B200 Blackwell (810 mm) avec 208 milliards de transistors répartis sur deux dies contenants chacune 104 milliards de transistors reliés par des interconnexions NVLink 5.0. Le GH100 comptait 80 milliards de transistors, de sorte que chaque die du B200 contient environ 30 % de transistors en plus, ce qui représente un gain modeste par rapport aux précédentes propositions. C'est la raison pour laquelle Nvidia utilise plus de puces pour son GPU complet et rivalise avec le GPU MI300X d’AMD (15 000$ HT environ). De type multi-puces, le B200 (80 000$ HT environ) est présenté comme un GPU Cuda unifié capable d’apporter plus de performances. L'élément clef est la liaison E/S à large bande passante entre les matrices, que le fournisseur appelle NV-High Bandwidth Interface (NV-HBI), et qui offre une bande passante de 10 To/s. Au total, le B200 offre 192 Go de HBM3E, soit 24 Go/stack, ce qui est identique à la capacité de 24 Go/stack du H200 (et 50 % de mémoire en plus par rapport au H100).

Gravé en 4 nm chez TSMC, le GPU B200 est composé de deux dies pour un total de 208 milliards de transistors. (Crédit Nvidia)
Moteur de transformation de seconde génération
L'une des grandes avancées de Nvidia avec Hopper, d'un point de vue architectural, a été la décision d'optimiser son accélérateur pour les modèles de type transformeur grâce à l'inclusion d'un matériel spécialisé, que le fournisseur appelle son moteur de transformation (Transformer Engine). "Le moteur de transformation, tel qu'il a été inventé à l'origine par Hopper, permet de suivre la précision et la plage dynamique de chaque couche de chaque tensor dans l'ensemble du réseau neuronal au fur et à mesure qu'il progresse dans le calcul", a indiqué M. Buck lors du point presse. "Au fur et à mesure que le modèle s'entraîne, nous surveillons constamment les plages de chaque couche et nous nous adaptons pour rester dans les limites de la précision numérique afin d'obtenir les meilleures performances", souligne-t-il. Tout en précisant, "Dans Hopper, cette comptabilité s'étend à un historique de 1 000 voies pour calculer les mises à jour et les facteurs d'échelle afin de permettre à l'ensemble du calcul d'être effectué avec une précision de seulement huit bits. Avec Blackwell, nous allons encore plus loin. Au niveau matériel, nous pouvons ajuster la mise à l'échelle de chaque tenseur. Blackwell prend en charge la mise à l'échelle des micro-tenseurs, non pas pour l'ensemble du tenseur, que nous pouvons toujours surveiller, mais pour chaque élément du tenseur. Pour aller plus loin, le moteur de transformation de deuxième génération de Blackwell nous permettra de porter le calcul d'IA à FP4, c'est-à-dire d'utiliser seulement une représentation en virgule flottante de quatre bits pour effectuer le calcul d'IA."
Il précise, "cela représente quatre zéros et un pour chaque neurone, chaque connexion - littéralement les chiffres de 1 à 16. Atteindre ce niveau de granularité fine est un miracle en soi. Le moteur Transformer de seconde génération effectue ce travail en combinaison avec la mise à l'échelle des micro-tenseurs de Blackwell, ce qui signifie que nous pouvons fournir deux fois plus de calculs qu'auparavant, nous pouvons doubler la bande passante effective parce que passer de huit bits à quatre bits, c'est la moitié de la taille. Et bien sûr, un modèle deux fois plus grand peut tenir sur un GPU individuel". En tirant parti du fait que les transformeurs n'ont pas besoin de traiter toutes les requêtes avec une grande précision (FP16), Nvidia ajoute donc la possibilité de mélanger ces opérations avec des calculs de moindre précision (FP8) afin de réduire les besoins en mémoire et d'améliorer le débit. Cette décision s'est avérée très payante lorsque OpenAI est arrivé en 2022 avec ChatGPT (GPT-3), qui a pleinement exploité les capacités à géométrie variable des puces H100. Lors de sa keynote, le CEO de Nvidia Jenseng Huang a indiqué, à titre de comparaison, que l'entraînement du chatbot ChatGPT d’OpenAiI avait été réalisé avec en trois mois avec 8 000 GPU Hopper et une puissance de 15 mégawatts. Avec Blackwell, 2 000 puces et 4 mégawatts auraient été nécessaires dans le même laps de temps.
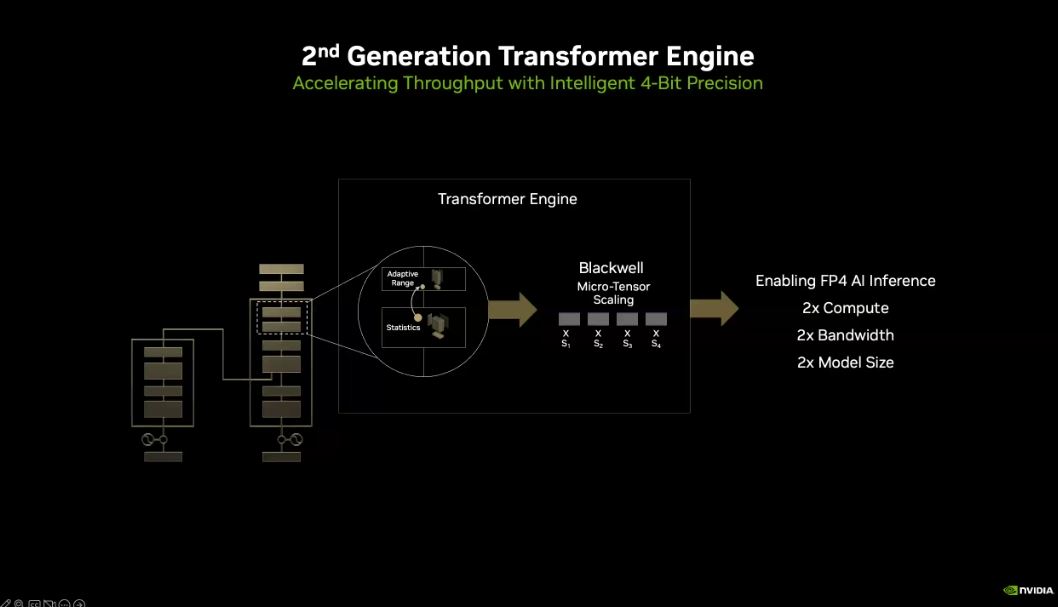
Nvidia inaugure sa seconde génération de moteur de transformation (Transformer Engine) pour accélération les traitements IA. (Crédit Nvidia)
Avec les moteurs de calcul Hopper et maintenant Blackwell, les grands modèles de langage qui soutiennent l'IA générative poussent l'architecture encore plus loin pour réduire le coût des charges de travail de formation et d'inférence de l'IA de plus en plus importantes. "L'année dernière, en 2023, nous avons assisté à la naissance de l'IA générative multimodale, où le texte parle aux images, les images peuvent créer des textes, l'audio peut créer de la 3D - et pas seulement dans les modalités humaines, mais dans des domaines scientifiques tels que la météo ou l'ADN, les molécules et les protéines et la découverte de médicaments", a souligné Ian Buck, vice-président en chrage de l’activité HPC chez Nvidia, lors d'un prébriefing le vendredi 15 mars. " Un nouveau type d'IA est en train d'émerger. Il s'agit d'une IA encore plus intelligente, construite non pas comme un modèle d'IA unique, mais comme une collection de modèles d'IA, appelée mélange de modèles experts - comme Google Gemini ou Meta NLLB ou Mistral AI et, bien sûr, OpenAI GPT-4. Ces nouveaux modèles prennent en fait plusieurs modèles d'IA et les font fonctionner de concert. Et pour chaque couche d'un transformateur, ils partagent leurs informations pour décider qui a la meilleure réponse pour la couche suivante afin de construire des modèles encore plus intelligents. Cela permet à l'IA de s'étendre davantage - jusqu'à des modèles de plusieurs billions de paramètres - ce que nous n'avons jamais vu auparavant. Bien entendu, le défi à relever est celui de l'informatique. Comme les modèles sont de plus en plus grands, l'entraînement nécessite plus de calcul. De plus, l'inférence représente une part de plus en plus importante du défi”.
Pour son moteur de transformation de deuxième génération, Nvidia va descendre encore plus bas dans ses calculs pour répondre aux besoins en IA. Blackwell sera capable de gérer des formats de nombres jusqu'à la précision FP4 dans le but d'utiliser ce format pour l'inférence. Le fournisseur envisage également d'effectuer davantage d'entraînements en FP8, ce qui permet de maintenir un débit de calcul élevé et une faible consommation de mémoire. Selon Nvidia, un accélérateur B200 assure jusqu'à 10 Pétaflops de performances en FP8 – soit environ 2,5 fois celles du H100 - et 20 PFLOPS en FP4 pour l'inférence. À l'autre bout du spectre, Nvidia a été très discret durant son point presse du 15 mars au sujet des performances en FP32 et FP64. S'ils sont peu utiles pour la grande majorité des charges de travail IA, ils sont indispensables pour le HPC. Les benchmarks de Nvidia sont toutefois arrivés par la suite avec 2,25 Pétaflops en FP16 (contre 1,8 pour le H100), et 40 Téraflops en FP64 (contre 30 pour le H100). Certaines informations restent toutefois difficiles à obtenir, les communiqués de presse étant loin d’être suffisamment détaillés.

Les liens NVLink et NVLinl Switch assurent l'interconnexion entre les GPU et entre les serveurs.
Les DGX passent à l’eau
Grâce aux progrès réalisés avec le pont NVLink (interconnexion GPU/GPU directe au sein du serveur sans passer par le PCI-e), les hyperscalers, les centres de recherche et bien sûr l’industrie peuvent étroitement coupler la mémoire et les ressources en calcul de dizaines de milliers de GPU et de centaines de serveurs (via InfiniBand ou Ethernet) pour mettre en place des supercalculateurs capables d’exécuter plus rapidement des charges de travail HPC (IA, simulation ou autre) et d'analyse de données. Il existe plusieurs itérations des serveurs DGX chez le fournisseur de Santa Clara, allant de 8 à 256 accélérateurs Hopper et dont les prix commencent à 500 000 $HT et s'échelonnent jusqu'à plusieurs millions de dollars. Nvidia suit une structure de configuration similaire pour la génération Blackwell, mais aucun prix n'est encore disponible. Le système Nvidia GB200 NVL72 se situe au sommet de la gamme. Il s'agit d'un système de 72 nœuds, refroidi par eau, à l'échelle du rack, destiné aux charges de travail les plus intensives. Chaque système DGX GB200 comprend 36 Superchips Grace Blackwell (72 GPU Blackwell et 36 CPU Grace sur base Arm) reliés par l'interconnexion NVLink 5.0 de dernière génération. La plateforme agit comme un seul GPU avec 1,4 exaflops de performance IA et 30 To de mémoire rapide.

Les serveurs DGX GB200 exploitent désormais des CPO Superchips Grace avec deux circuits G200. (crédit Nvidia)
Ces systèmes DGX offrent une toute nouvelle forme de communication entre les puces, a déclaré Charlie Boyle, vice-président des systèmes DGX chez Nvidia. Sur un très gros travail de formation à l'IA, vous pouvez passer 60 % du temps à échanger des données avec les GPU. Si vous pouvez augmenter la vitesse du réseau en le plaçant sur NVlink, qui est un réseau basé sur la mémoire et non un réseau de base de données traditionnel, vous pouvez effectuer ce travail de manière beaucoup plus efficace", a-t-il déclaré. Un rack DGX est une armoire 44U comprenant 18 noeuds de calcul, neuf plateaux de commutation, deux unités de distribution d'énergie, un commutateur de gestion d'énergie, un collecteur de refroidissement liquide et un fond de panier NVlink. Jusqu'à présent, les systèmes DGX étaient refroidis par air - il s'agit de la première unité dotée d'un système de refroidissement liquide, ce qui constitue un aveu tacite que ces systèmes sont très chauds. M. Boyle a refusé de commenter les rumeurs selon lesquelles le processeur Blackwell fonctionnerait à plus de 1 000 watts, comme l’avait indiqué Dell. C'est une question d'efficacité et de densité, a déclaré M. Boyle. Pour obtenir 72 GPU dans un rack et obtenir ce NVlink, il faut que ce soit très dense à l'intérieur. Nous mettons cette technologie à la disposition de nos partenaires OEM et ODM. Ils peuvent choisir de proposer différentes configurations, différentes densités. Mais pour le produit vendu sous le nom DGX, il est refroidi par eau en raison de la haute densité du système.

Les DGX SuperPod sont passés au refroidissement par eau avec l'architecture Blackwell. (Crédit Nvidia)
Des fonctionnalités RAS
La dernière version du DGX SuperPOD avec les systèmes DGX GB200 ne rendra pas les autres versions obsolètes, mais elle possède des capacités uniques qui ne se retrouvent que dans ce système. Par exemple, les fonctions RAS (fiabilité, disponibilité, évolutivité) sont intégrées dans la puce et s'étendent au serveur avec des capacités telles que la maintenance prédictive, la santé du système et la surveillance de milliers de points de données à tout moment. Nvidia a développé le programme DGX Ready pour les centres de données ; elle a travaillé avec ses partenaires pour qu'ils soient prêts à accueillir ces systèmes avec un minimum d'efforts de mise en place, ce qui inclut le refroidissement liquide. “Lorsque ces systèmes seront livrés aux clients, et je pense que la plupart d'entre eux finiront dans des centres de données de colocation, certains clients ont du liquide natif et d'autres construisent des datacenters de nouvelle génération, mais nous facilitons les choses pour les clients qui veulent l'adopter", a-t-il déclaré. Les systèmes DGX devraient être livrés dans le courant de l'année.
Commentaire