")
Il s’appelle Bench, tout simplement. Un raccourci de benchmarking ou analyse comparative en français et n’est rien de plus que cela. Cet outil, présenté comme open source et dédié à l’évaluation et à la comparaison des performances de grands modèles de langage (LLM), est le résultat du travail réalisé par la start-up Arthur spécialisée dans l’IA. Cette solution doit notamment traiter des modèles tels que GPT-3.5 Turbo d'OpenAI et LLaMA 2 de Meta. Avec Bench, les entreprises peuvent tester les performances de différents modèles linguistiques sur des cas d'utilisation spécifiques. Dans le détail, l’outil apporte un comparatif sur aspects de précision, de lisibilité, de couverture et d'autres critères.
Par couverture, on entend ici un problème spécifique : c'est lorsqu'un LLM fournit un langage supplémentaire résumant ou faisant allusion à ses conditions de service, ou à des contraintes de programmation, telles que « en tant que modèle de langage d'IA... », qui n'est généralement pas en rapport avec la réponse souhaitée par l'utilisateur. Conçu en open source, les entreprises qui l'utilisent peuvent donc ajouter leurs propres critères pour répondre à leurs propres besoins. In fine, Bench doit aider les entreprises à évaluer les performances de différents LLM dans des scénarios réels afin qu'elles puissent ensuite « prendre des décisions éclairées et fondées sur des données lorsqu'elles intègrent les dernières technologies d'IA dans leurs activités », précise la société dans un communiqué.
Un couteau suisse de l’IA pour les entreprises
Bench est le dernier-né de la gamme de produits d'Arthur centrés sur le LLM, après Shield en mai. Pour mémoire, Shield s’occupe de la surveillance des grands modèles de langage afin de détecter les hallucinations et d'autres problèmes. Les entreprises peuvent recourir à Bench de multiples façons. Tout d’abord, par la sélection et la validation de modèles. « Le paysage de l’IA évolue rapidement. Il est essentiel de se tenir au courant des avancées et de s'assurer que le choix du LLM d'une entreprise reste le meilleur en termes de viabilité des performances », détaille la société. En s’appuyant sur une métrique cohérente, les entreprises déterminent ainsi le meilleur choix pour leur application. La solution répond également à des problématiques d’optimisation du budget et de la confidentialité. En effet, toutes les applications ne nécessitent pas les LLM les plus avancés ou les plus coûteux. « Dans certains cas, un modèle d'IA moins coûteux peut effectuer les tâches requises tout aussi bien. Par exemple, si une application génère du texte simple, comme des réponses automatisées à des questions courantes de clients, un modèle moins coûteux pourrait suffire. En outre, l'exploitation de certains modèles et leur intégration en interne donnent la possibilité mieux contrôler la confidentialité des données ».
Bench apporte par ailleurs la capacité de récupérer les 100 dernières questions posées par les utilisateurs et les comparer à tous les modèles. « [L’outil] met ensuite en évidence les réponses les plus différentes afin que vous puissiez les examiner manuellement », explique Adam Wenchel, CEO et co-fondateur d’Arthur. « Avec Bench, nous avons créé un outil open-source pour aider les équipes à comprendre en profondeur les différences entre les fournisseurs de LLM, les différentes stratégies d'incitation et d'augmentation et les régimes d'entraînement personnalisés », ajoute-t-il. Tout ceci repose sur une combinaison de mesures et de scores statistiques ainsi que l'évaluation d'autres LLM pour classer côte à côte les réponses des LLM souhaités.
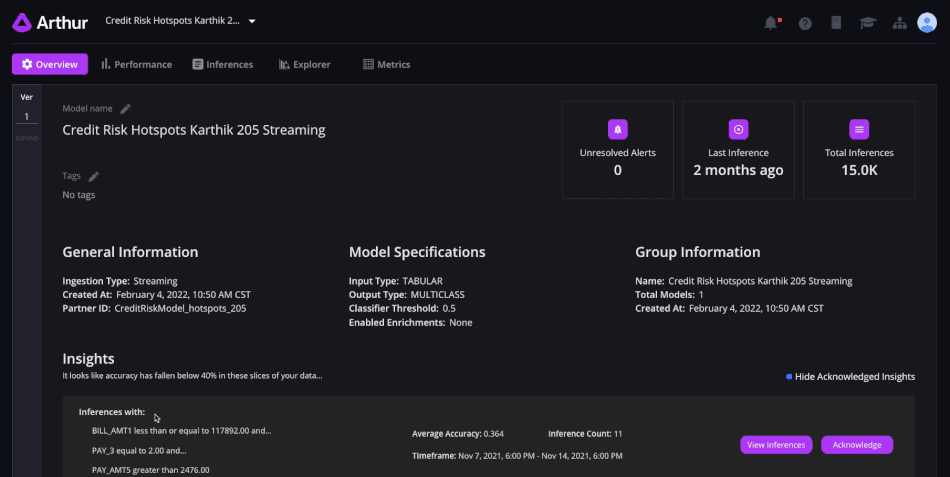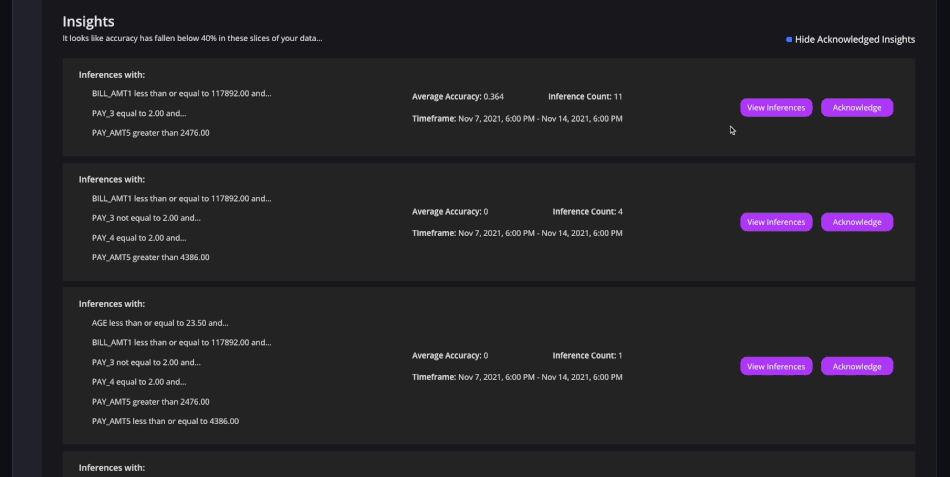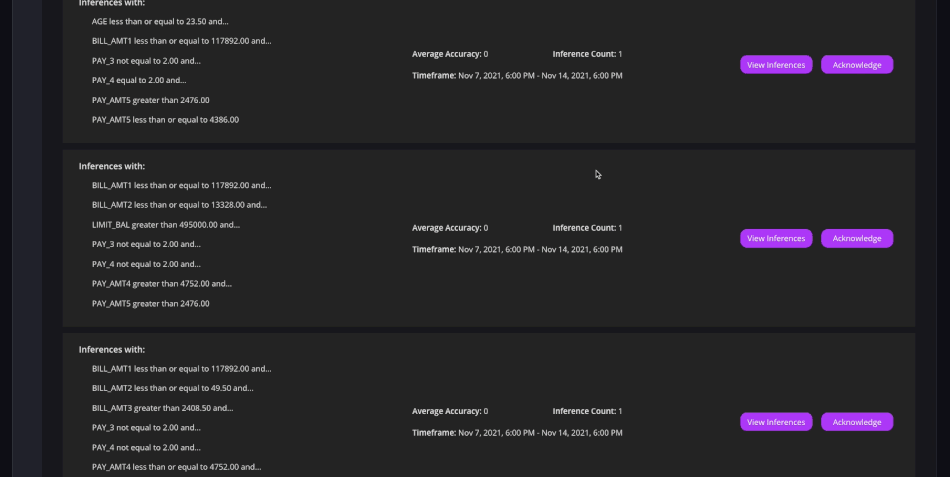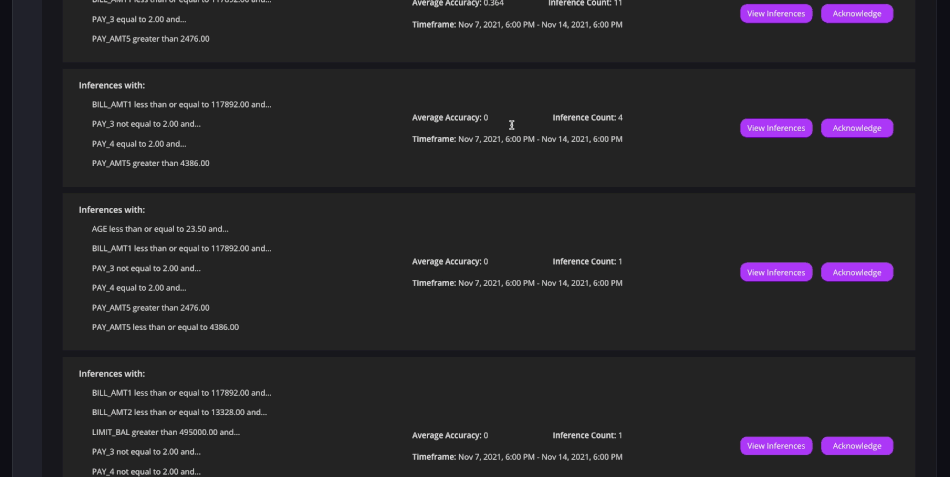
Avec Arthur, les entreprises peuvent détecter proactivement les mauvaises performances de certains modèles en fonction de seuils prédéfinis. (Crédit : Arthur)
Des services financiers et constructeurs automobiles séduits
A ce jour, Bench est utilisé notamment par des sociétés de services financiers – à l’instar d’Axios HQ – afin de produire plus rapidement des théories et des analyses d'investissement. « Bench nous a aidés à développer un cadre interne pour mettre à l'échelle et standardiser l'évaluation LLM à travers les fonctionnalités, et pour décrire la performance à l'équipe produit avec des métriques significatives et interprétables », a déclaré Priyanka Oberoi, responsable d'équipe data scientist chez Axios HQ, qui a notamment eu un accès anticipé à la solution.
Arthur prévoit également de cibler d’autres secteurs et précise que les constructeurs automobiles sont très intéressés. « Les constructeurs automobiles ont pris leurs manuels d'équipement contenant de nombreuses pages de conseils techniques très spécifiques et ont utilisé Arthur Bench pour créer des LLM capables de répondre aux questions des clients tout en recherchant des informations dans ces manuels de manière rapide et précise, tout en réduisant les hallucinations ».
Une initiative lancée en parallèle pour classer les +/- des LLM
La jeune pousse a également dévoilé The Generative Assessment Project (GAP), une initiative de recherche classant les forces et les faiblesses des modèles de langage proposés par les leaders du secteur tels que OpenAI, Anthropic et Meta. Les recherches d'Arthur suggèrent notamment qu'Anthropic pourrait gagner un léger avantage concurrentiel par rapport à GPT-4 d'OpenAI sur les mesures de « fiabilité » dans des domaines spécifiques. Par exemple, alors que GPT-4 était le plus performant pour répondre aux questions de mathématiques, le modèle Claude-2 d'Anthropic était plus performant pour éviter les erreurs factuelles hallucinées et pour répondre « je ne sais pas » au bon moment aux questions d'histoire.
Avec GAP, Arthur affirme qu’il continuera à partager avec le public ses découvertes sur les différences de comportement et les meilleures pratiques, dans le cadre de sa démarche visant à rendre les LLM accessibles à tous. « Comme le montre clairement notre recherche GAP, la compréhension des différences de performance entre les LLM peut être incroyablement nuancée », ajoute Adam Wenchel.
Des collaborations avec AWS et Cohere
En parallèle, Arthur a aussi annoncé un hackathon avec Amazon Web Services (AWS) et Cohere pour encourager les développeurs à créer de nouvelles mesures pour sa solution Bench. Son fondateur a déclaré que l'environnement Bedrock d'AWS pour choisir et déployer une variété de LLM était « très aligné philosophiquement » avec Arthur Bench.
Commentaire