")
Les chatbots tels que ChatGPT, Claude.ai et phind sont sans doute très utiles, mais les entreprises ne souhaitent pas toujours que les données sensibles soient traitées par une application externe. C'est particulièrement vrai sur les plateformes où les interactions sont examinées par des humains et utilisées pour former de futurs modèles. Une solution consiste à télécharger un modèle de langage étendu (LLM) et à l'exécuter sur un de ses systèmes. Une façon de s'assurer qu’aucune autre entreprise extérieure n'accèdera jamais à ces données. Une occasion aussi pour essayer de nouveaux modèles spécialisés, tels que la famille de modèles Code Llama de Meta récemment annoncée et adaptée au développement, et SeamlessM4T destiné à la synthèse vocale et aux traductions linguistiques.
L'exploitation de son propre LLM peut sembler compliquée, mais avec les bons outils cela devient étonnamment facile, sachant que les exigences matérielles pour de nombreux modèles ne sont pas folles. Les scénarios d’usage présentés ci-dessous tournent sur deux systèmes : un PC Dell équipé d'un processeur Intel i9, de 64 Go de RAM et d'un GPU Nvidia GeForce 12 Go (qui n'a probablement pas été utilisé pour faire tourner la plupart de ces logiciels). Et un Mac doté d'une puce M1 mais de seulement 16 Go de RAM. Simon Willison, créateur de l'outil en ligne de commande LLM, a fait valoir lors d'une présentation la semaine dernière qu'il pouvait être intéressant d'utiliser un modèle local même si ses réponses sont erronées : « Je pense que c'est une excellente raison de les utiliser, car l'utilisation de modèles faibles sur un ordinateur portable est un moyen beaucoup plus rapide de comprendre le fonctionnement et les limites de ces outils ».
Petite précision à savoir : il faudra peut-être un peu de recherche pour trouver un modèle qui fonctionne raisonnablement bien pour une tâche donnée et qui s'exécute sur un matériel de bureau. En outre, rares seront sans doute les utilisateurs à maitriser tous les outils aussi bien qu’il est possible de le faire avec ChatGPT (en particulier avec GPT-4) ou Claude.ai. Il convient également de noter que les modèles open source devraient continuer à s'améliorer, et certains observateurs du secteur s'attendent à ce que l'écart entre ces modèles et les leaders commerciaux se réduise.
Exécuter un chatbot local avec GPT4All
En recherche d'un chatbot qui fonctionne localement et n'envoie pas de données ailleurs, GPT4All propose un client de bureau à télécharger qui est assez facile à configurer. Il comprend des options pour les modèles qui fonctionnent sur son propre système, et il existe des versions pour Windows, macOS et Ubuntu. Lorsque l’on ouvre l'application de bureau GPT4All pour la première fois, des options pour télécharger une dizaine de modèles (à l'heure où nous écrivons ces lignes) fonctionnent localement. Parmi eux figure Llama-2-7B, un modèle de Meta AI. On peut également configurer les modèles GPT-3.5 et GPT-4 d'OpenAI (sous réserve d’y avoir accès) pour une utilisation non locale en disposant d'une clé API.
La partie de l'interface GPT4All consacrée au téléchargement des modèles était un peu confuse au début. Après avoir téléchargé plusieurs modèles, l'option pour tous les télécharger est encore présente, suggérant que les téléchargements ne fonctionnaient pas. Cependant, une vérification de chemin de téléchargement montrait bien que les modèles étaient là.
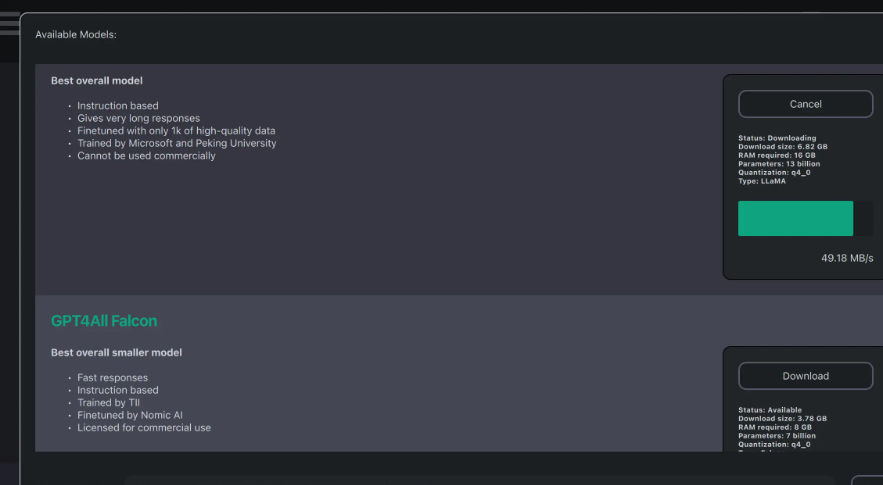
Une partie de l'interface de téléchargement de modèles dans GPT4All. Une fois que j'ai ouvert la partie utilisation de l'application, mes modèles téléchargés sont apparus automatiquement.
Une fois les modèles mis en place, l'interface du chatbot est propre et facile à utiliser. Les options pratiques comprennent la copie d'un chat dans le presse-papiers et la génération d'une réponse. (crédit : Sharon Machlis)
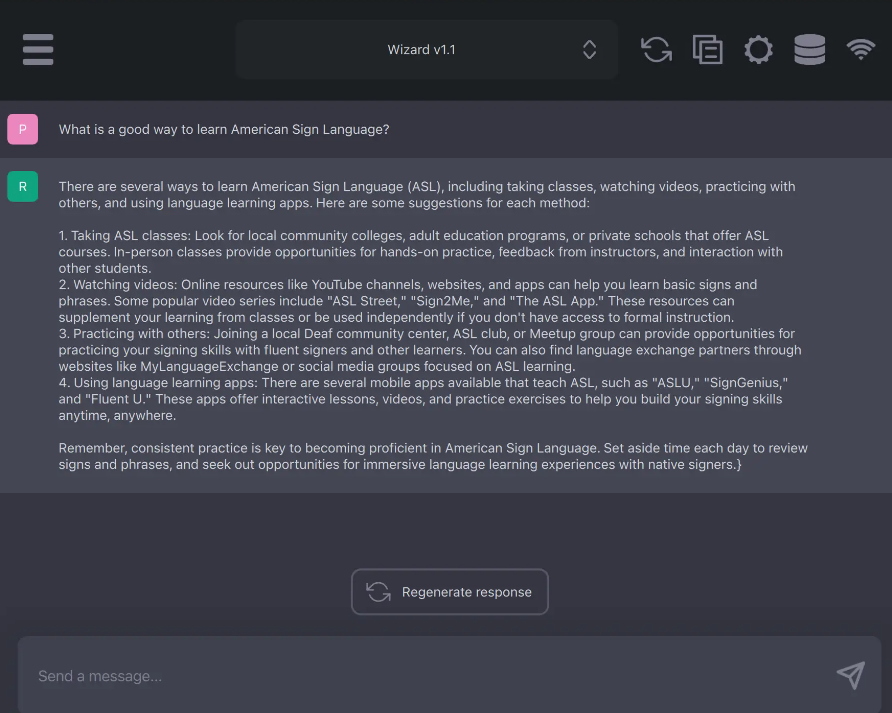
L'interface de chat de GPT4All est propre et facile à utiliser. (crédit : Sharon Machlis)
Il existe également une version bêta du plugin LocalDocs pour « chatter » avec ses propres documents localement. Il est possible de l'activer dans l'onglet Paramètres > Plugins, où sera indiqué en en-tête « LocalDocs Plugin (BETA) Settings » et une option pour créer une collection dans un chemin de dossier spécifique.
Le plugin est en cours d'élaboration et la documentation prévient que le LLM peut encore « halluciner » (inventer des choses) même s'il a accès aux informations d'expert ajoutées. Néanmoins, il s'agit d'une fonctionnalité intéressante qui devrait s'améliorer au fur et à mesure que les modèles open source deviendront plus performants. En plus de l'application de chatbot, GPT4All a également des liens pour Python, Node et une interface de ligne de commande (CLI). Il existe également un mode serveur pour interagir avec le LLM local par le biais d'une API HTTP structurée de manière très similaire à celle d'OpenAI. L'objectif est d’être en capacité de remplacer un LLM local par OpenAI en changeant quelques lignes de code.
Les LLM en ligne de commande
Le LLM de Simon Willison est l'un des moyens les plus simples pour télécharger et utiliser des LLM open source localement sur sa propre machine. Bien qu'il n'y a pas besoin d'installer Python pour le faire fonctionner, on ne doit pas avoir besoin de toucher au code Python. En cas d'utilisation d'un Mac et d'Homebrew, il faut simplement l'installer avec « brew install llm ». Avec un système Windows, il faudra recourir à l'installation de bibliothèques Python telle que « pip install llm ».
Ce LLM par défaut n’utilise pas les modèles OpenAI, mais il est possible d’utiliser des plugins pour exécuter d'autres modèles localement. Par exemple, en installant le plugin gpt4all, l’utilisateur aura accès à des modèles locaux supplémentaires de GPT4All. Il existe également des plugins pour Llama, le projet MLC et MPT-30B, ainsi que des modèles distants supplémentaires. L’installation d’un plugin en ligne de commande se fait avec llm install model-name: llm install llm-gpt4all. Il est possible de voir tous les modèles disponibles - à distance et ceux installés -, y compris de brèves informations sur chacun d'entre eux, avec la commande : llm models list.

L'écran qui s'affiche lorsque l’on demande au LLM de dresser la liste des modèles disponibles. (crédit : Sharon Machlis)
L’envoi d’une requête à un LLM local se fait en utilisant la syntaxe suivante : llm -m the-model-name "Your query". Ensuite on peut poser une question à la manière de ChatGPT sans lancer de commande distincte pour télécharger le modèle : llm -m ggml-model-gpt4all-falcon-q4_0 "Tell me a joke about computer programming".
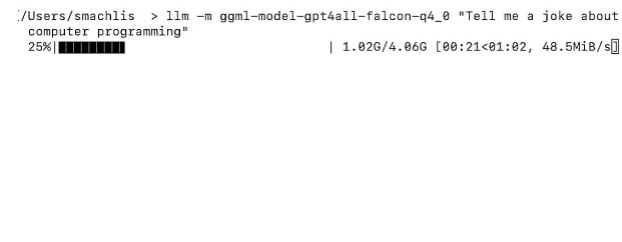
Le LLM a automatiquement téléchargé le modèle utilisé dans une requête déterminée. (crédit : Sharon Machlis)
On peut ensuite tester avec une blague qui vaut ce qu'elle vaut : « Pourquoi un programmeur éteint-il son ordinateur ? Pour voir s'il fonctionne encore ! » ; mais la requête a en fait fonctionné. Et si les résultats sont décevants, c'est à cause de la performance du modèle ou de l'inadéquation des messages-guides de l'utilisateur et non pas à cause de l'outil LLM. Il est également possible de définir des alias pour les modèles dans LLM pour les désigner par des noms plus courts : llm aliases set falcon ggml-model-gpt4all-falcon-q4_0. Pour voir tous les alias disponibles, il faut entrer : llm aliases.
Le plugin LLM pour les modèles Llama de Meta nécessite un peu plus d'installation que GPT4All. Notez que Llama-2-7b-chat à usage général a réussi à fonctionner sur un Mac avec la puce M1 Pro et seulement 16 Go de RAM. Il a fonctionné plutôt lentement comparé aux modèles GPT4All optimisés pour les petites machines sans GPU, et a même mieux fonctionné sur un PC personnel plus robuste. Cen LLM possède d'autres fonctionnalités, telles qu'un indicateur d'argument pour reprendre à partir de là où l’on s’était arrêté dans un chat précédent et la possibilité de l'utiliser dans un script Python. Simon Willison, co-créateur du célèbre framework Python Django, espère que d'autres membres de la communauté contribueront à l'écosystème LLM en y ajoutant d'autres plugins.
Des modèles Llama sur Mac avec Ollama
Ollama est un moyen encore plus facile de télécharger et d'exécuter des LLM, bien qu'il soit également plus limité. Pour l'instant, il n'existe que sous macOS, mais la prise en charge de Windows et de Linux est prévue pour bientôt.
L'installation d'Ollama est très simple. (crédit : Sharon Machlis)
L'installation se fait élégamment par pointer-cliquer. Et bien qu'Ollama soit un outil en ligne de commande, il n'y a qu'une seule commande avec la syntaxe ollama run model-name. Comme pour tout LLM, si le modèle n'est pas déjà sur son système, il sera automatiquement téléchargé. Il est possible de consulter la liste des modèles disponibles à cette adresse qui, à l'heure où nous écrivons ces lignes, comprenait une version d'un modèle de Code Llama, mais aucune des options adaptées à Python. Mais d'autres devraient être disponibles dans le futur. Le README de la version GitHub d'Ollama comprend une liste utile des spécifications de certains modèles et le conseil suivant : « Vous devez disposer d'au moins 8 Go de RAM pour faire fonctionner les modèles 3B, 16 Go pour faire fonctionner les modèles 7B, et 32 Go pour faire fonctionner les modèles 13B ». Sur un Mac doté de 16 Go de RAM, les performances du lama-code 7B ont été étonnamment rapides. Il répondra aux questions concernant les commandes de l'interpréteur de commandes bash/zsh ainsi que les langages de programmation tels que Python et JavaScript.
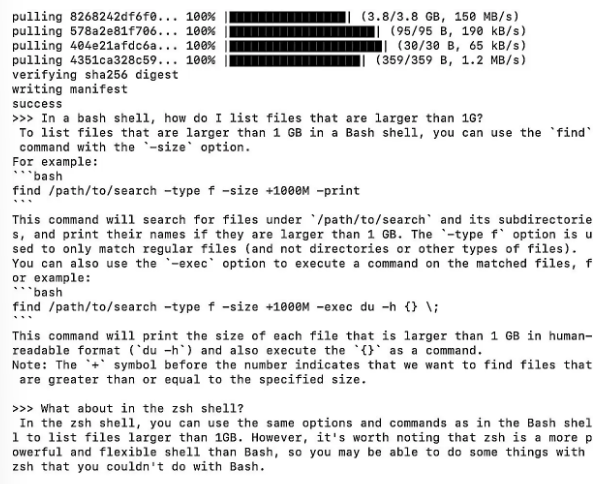
Ce que cela donne en exécutant Code Llama dans une fenêtre de terminal Ollama. (crédit : Sharon Machlis)
Bien qu'il s'agisse du plus petit modèle de la famille, il s'est avéré assez bon, bien qu'imparfait, pour répondre à une question de codage R qui a fait trébucher certains modèles plus grands : « Écrivez le code R d'un graphique ggplot2 dont les barres sont de couleur bleu acier ». Le code était correct à l'exception de deux parenthèses fermantes supplémentaires dans deux des lignes de code, qui étaient assez faciles à repérer dans mon IDE. On peut soupçonner qu'un code Llama plus grand aurait pu faire mieux. Ollama possède quelques fonctionnalités supplémentaires, telles que l'intégration de LangChain et la possibilité de fonctionner avec PrivateGPT, qui peuvent ne pas être évidentes si on ne consulte pas la page de tutoriels du dépôt GitHub. Pour les utilisateurs Mac souhaitant utiliser Code Llama, il est possible de le faire tourner dans une fenêtre de terminal et le faire apparaître à chaque fois que vous avez une question. Mais à quand une version Windows d'Ollama pour l'utiliser sur un PC personnel ? On se le demande bien...
Chat avec vos propres documents : h2oGPT
H2O.ai travaille sur l'apprentissage automatique depuis un certain temps, il est donc naturel que l'entreprise se soit lancée dans l'espace LLM du chat. Certains de ses outils sont mieux utilisés par des personnes ayant des connaissances dans le domaine, mais les instructions pour installer une version test de son application de bureau h2oGPT ont été rapides et simples, même pour les novices en matière d'apprentissage automatique. Vous pouvez accéder à une version de démonstration sur le web (évidemment sans utiliser un LLM local à votre système) à l'adresse gpt.h2o.ai, ce qui est un moyen utile de découvrir si vous aimez l'interface avant de la télécharger sur votre propre système.
Pour une version locale : clonez le dépôt GitHub, créez et activez un environnement virtuel Python, et exécutez les cinq lignes de code trouvées dans le fichier README. Les résultats donnent une « capacité limitée de Q/A des documents » et l'un des modèles Llama de Meta, selon la documentation, mais ils fonctionnent. Une version du modèle Llama sera téléchargée localement et une application sera disponible à l'adresse http://localhost:7860 après l'exécution d'une seule ligne de code : python generate.py --base_model='llama' --prompt_type=llama2.
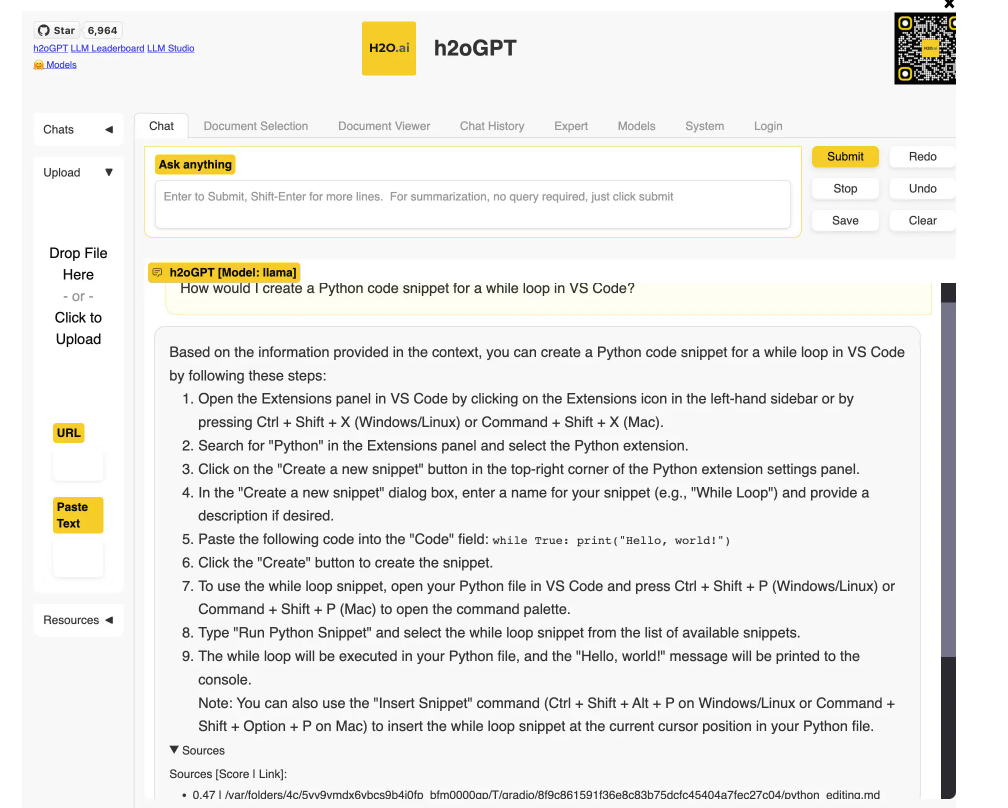
Un modèle local LLaMa répond aux questions basées sur la documentation VS Code. (crédit : Sharon Machlis)
Sans ajouter ses propres fichiers, on peut utiliser l'application comme un chatbot général. Il est aussi possible de télécharger des documents et poser des questions sur ces fichiers. Les formats de fichiers compatibles sont les suivants : PDF, Excel, CSV, Word, texte, markdown, etc. L'application de test a bien fonctionné sur un Mac 16 Go, bien que les résultats du petit modèle ne soient pas comparables à ceux de ChatGPT avec GPT-4 (comme toujours, cela dépend du modèle et non de l'application). L'interface utilisateur de h2oGPT propose un onglet Expert avec un certain nombre d'options de configuration pour les utilisateurs qui savent ce qu'ils font. Les utilisateurs plus expérimentés ont ainsi la possibilité d'essayer d'améliorer leurs résultats.
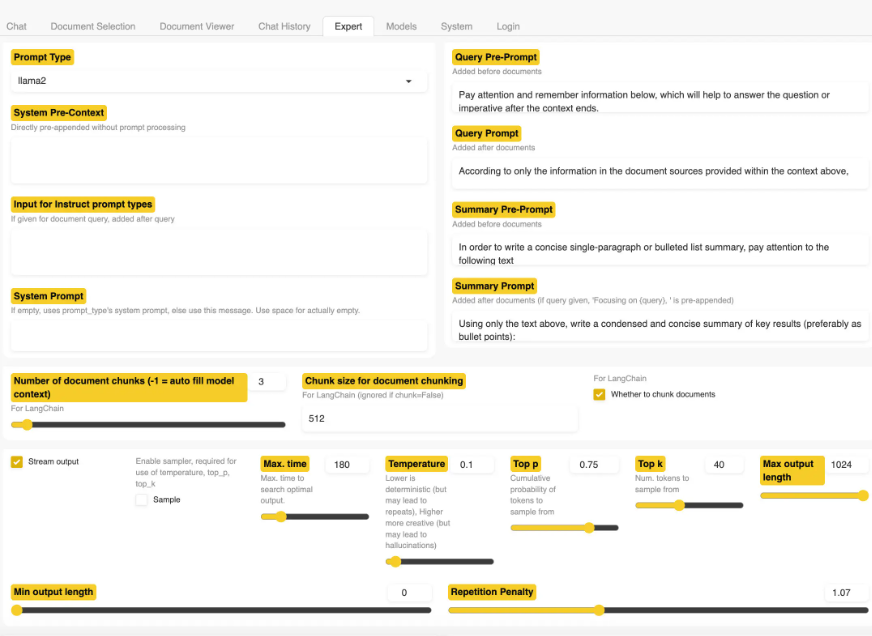
Exploration de l'onglet Expert de h2oGPT. (crédit : Sharon Machlis)
Pour ceux qui souhaitent avoir plus de contrôle sur le processus et des options pour plus de modèles, il faut télécharger l'application complète, bien que cela puisse demander plus de travail pour faire fonctionner un modèle sur un matériel limité. Le fichier README contient des instructions d'installation pour Windows, macOS et Linux. A savoir que le logiciel antivirus Windows utilisé dans le cadre de ce présent test n'était pas « satisfait » parce qu'elle était à la fois nouvelle et non signée. Cependant, d'autres logiciels de H2O.ai dont le code est disponible sur GitHub, pouvaient aussi faire l'affaire, mais en fin de compte, en absence de puissance GPU nécessaire pour faire tourner un modèle de taille décente, il est conseillé plutôt d'installer le logiciel à partir de la source. Rob Mulla, qui travaille maintenant chez H2O.ai, a d'ailleurs publié sur sa chaîne une vidéo YouTube l'installation de l'application sous Linux. Bien que la vidéo date de quelques mois et que l'interface utilisateur de l'application semble avoir changé, elle contient toujours des informations utiles, y compris des explications sur les LLM de H2O.ai.
Chat facile mais lent avec vos données : PrivateGPT
PrivateGPT est également conçu pour interroger ses propres documents en utilisant le langage naturel et obtenir une réponse générative de l'IA. Les documents de cette application peuvent inclure plusieurs douzaines de formats différents. Le README assure que les données sont 100% privées et qu'aucune donnée ne quitte l'environnement d'exécution à aucun moment et qu'il est possible d'ingérer des documents et poser des questions sans connexion internet. PrivateGPT propose des scripts pour ingérer des fichiers de données, les diviser en morceaux, créer des « embeddings » (représentations numériques du sens du texte) et stocker ces embeddings dans un magasin local de vecteurs Chroma. Lorsque vous posez une question, l'application recherche les documents pertinents et les envoie au LLM pour générer une réponse.
Pour ceux familiers avec Python et qui savent mettre en place des projets Python, il est possible de cloner le dépôt complet de PrivateGPT et l'exécuter localement. Si c'est moins le cas, on peut consulter une version simplifiée du projet que l'auteur Iván Martínez a mis en place pour un atelier de conférence, et qui est considérablement plus facile à mettre en place. Le fichier README de cette version contient des instructions détaillées qui ne présupposent pas d'expertise en matière d'administration système Python. Le repo est livré avec un dossier source_documents rempli de documentation Penpot, mais on peut l'effacer et ajouter la vôtre. PrivateGPT inclut les fonctionnalités que vous souhaiteriez probablement trouver dans une application de « chat avec ses propres documents » dans le terminal, mais la documentation prévient qu'elle n'est pas destinée à la production. Et une fois lancé, on comprend pourquoi : même l'option petit modèle fonctionne très lentement sur un PC personnel. Mais il ne faut pas oublier pas que les premiers jours de l'Internet domestique étaient eux aussi terriblement lents. On peut donc s'attendre à ce que ce type de projets individuels s'accélère.
Plus de moyens pour gérer un LLM local
Il existe d'autres moyens d'exécuter des LLM localement que ces cinq-là, depuis d'autres applications de bureau jusqu'à l'écriture de scripts à partir de zéro, tous avec des degrés variables de complexité de configuration. Une version dérivée de PrivateGPT, LocalGPT, comprend plus d'options pour les modèles et dispose d'instructions détaillées ainsi que de trois vidéos pratiques, y compris un code détaillé de 17 minutes. Les avis peuvent diverger sur la question de savoir si cette installation et cette configuration sont « faciles », mais elles semblent prometteuses. Comme pour PrivateGPT, cependant, la documentation prévient que l'exécution sur un CPU seul sera lente. LM Studio, une autre application de bureau que j'ai essayée, dispose d'une interface facile à utiliser pour organiser des chats, mais on doit se débrouiller seul pour choisir les modèles. Si l'on sait quel modèle télécharger et utiliser, cela constitue un bon choix. Pour ceux qui viennent tout juste d'utiliser ChatGPT et ayant une connaissance limitée de la meilleure façon d'équilibrer la précision et la taille, tous les choix peuvent s'avérer être des fardeaux au début. Hugging Face Hub est la principale source de téléchargement de modèles dans LM Studio, et elle contient beaucoup de modèles.
Contrairement aux autres options LLM, qui ont toutes téléchargé les modèles choisis du premier coup, des problèmes pour télécharger l'un des modèles dans LM Studio sont survenus. Un autre n'a pas bien fonctionné, sans doute à cause d'une envie d'exploiter au maximum le matériel de mon Mac, alors qu'une suggestion de RAM minimum sans GPU pour les choix de modèles était proposée... Pour ceux qui n'ont pas peur d'être patient lors de la sélection et du téléchargement des modèles, LM Studio dispose d'une interface agréable et propre une fois que le chat est lancé. Au moment de la rédaction de ce document, l'interface utilisateur n'avait pas d'option intégrée pour exécuter le LLM sur vos propres données.
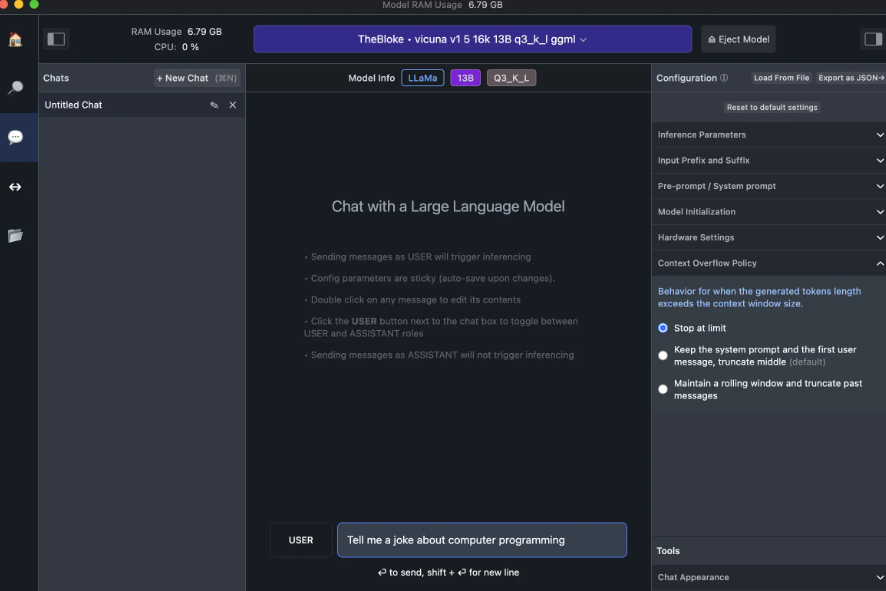
L'interface du studio LLM. (crédit : Sharon Machlis)
Il dispose d'un serveur intégré qui peut être utilisé « en remplacement de l'API OpenAI », comme l'indique la documentation, de sorte que le code qui a été écrit pour utiliser un modèle OpenAI via l'API s'exécutera à la place sur le modèle local que vous avez sélectionné. Comme h2oGPT, LM Studio affiche également un avertissement sur Windows indiquant qu'il s'agit d'une application non vérifiée. Le code de LM Studio n'est pas disponible sur GitHub et ne provient pas d'une organisation établie de longue date, donc tout le monde ne sera pas à l'aise pour l'installer.
En plus d'utiliser une interface de téléchargement de modèle pré-construite à travers des applications comme h2oGPT, vous pouvez également télécharger et exécuter certains modèles directement à partir de Hugging Face, une plateforme et une communauté pour l'intelligence artificielle qui comprend de nombreux LLM. Mais tous les modèles ne comportent pas d'options de téléchargement. Mark Needham, porte-parole des développeurs chez StarTree, propose une explication intéressante sur la manière de procéder, y compris une vidéo sur YouTube. Il dispose également d'un code connexe dans un repo GitHub, y compris l'analyse des sentiments avec un LLM local. Hugging Face propose également sa propre documentation sur la manière d'installer et d'exécuter localement les modèles disponibles.
Une autre option populaire consiste à télécharger et à utiliser les LLM localement dans LangChain, un framework pour créer des applications d'IA générative de bout en bout. Cela nécessite de se familiariser avec l'écriture de code dans l'écosystème LangChain. En connaissant les bases de LangChain, on peut consulter la documentation sur Hugging Face Local Pipelines, Titan Takeoff (nécessite Docker ainsi que Python), et OpenLLM pour exécuter LangChain avec des modèles locaux. OpenLLM est une autre plateforme robuste et autonome, conçue pour déployer en production des applications basées sur LLM.
Commentaire